This course is called "Computational Pragmatics", but it might be more accurately called "Doing pragmatics with computational resources".
The phrase "computational pragmatics" probably calls to mind dialogue systems and intelligent agents. While I think our explorations could inform research in those areas, they won't be our focus. Rather, we will concentrate on using computational resources (corpora, algorithms, etc.) to explore pragmatic phenomena.
The current plan goes roughly like this:
I am not sure what our pace will be, or whether will get diverted onto other topics, but this list should give you a sense for the kinds of things I have in mind to cover, as well as the resources available to you as part of this course.
Each Friday, I'll pick one or two of the exercise sections, which are at the bottoms of all the content pages. On the following Tuesday, you should submit, by email to , answers to at least two of those exercises. Most involve coding of some kind, but a handful from each section can be done without a computer.
On August 7, you should turn in a report on one of the project problems. These are more open-ended and involved than the regular exercises. I think any of them could be developed into something publishable. You're also welcome to define your own project.
This is a hands-on, experiment-driven course in computational pragmatics. Ideally, you will attend class with a laptop that is set up with R, Python, and NLTK, as described below.
If you don't have a laptop here, I hope you can get regular access here at the Institute to a computer with these tools on it, so that you can play around with the ideas outside of the classroom.
If you really have no computer access while here, you're still welcome to stay enrolled. In this case, talk to me during office hours, or drop me a note by email (). We might want to make special arrangements for the exercises and project problem.
If you have access to a computer while here, you should install the following:
I'm going to be using R and Python extensively, but the goal of the course is to study linguistic phenomena, not programming. You should feel free to use other programming tools. For example, if you are a whiz with the likes of Excel, MySQL, or SPSS, then you might prefer to stick with that instead of using R. Similarly, Perl, Ruby, Java, Scheme — these are all great for computational linguistics. Use whatever will get you as a swiftly as possible to doing analysis.
My main reasons for using Python: it's the currently optimal mix of (i) intuitive, (ii) efficient, (iii) well-supported by scientific libraries.
I rely on R for statistical analysis and visualization. This can be done in Python too, of course, but I think R is a more natural choice for these things.
I'm assuming that you have some programming experience. I'm not going to give explicit instruction in R or Python. Rather, we will just dive right in. The lectures and exercises will acquaint you with a wide range of tools and techniques, especially if you're willing to use the Web and documentation to fill in gaps. I'm also happy to answer programming questions during my office hours.
To prep for this, you might check out these useful materials:
R has a excellent graphical interface that will launch when you start it like any other program.
When you launch it, you'll be in interactive mode. Try some basic mathematical expressions. Here is some code you might try; paste it into the buffer and hit enter:
(The above is how I will display interactive R code, with the greater-than prompt, code in blue, comments in maroon, and output in black. This reflects the default style for the graphical interface.)
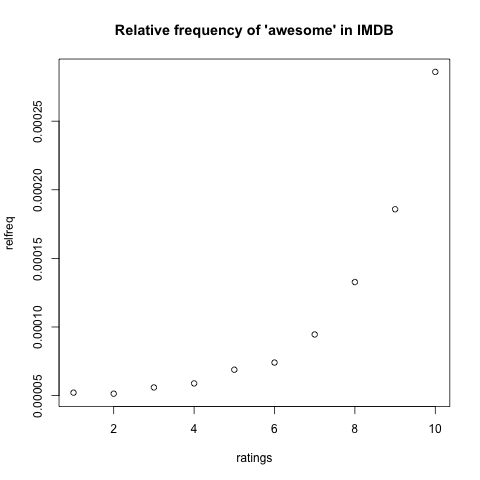
This should pop up on your screen (click to enlarge):
(For more on this kind of data.)
You can also put your R code into a separate file. Here is some code that you could paste into a text-editor (you can use R's by selecting File > New Document):
(This is how I will display R code presumed to be written and saved in a separate file — same style as in interactive mode, but with no > prompt.)
Save the file (I picked the name basic_plots.R). Now, back at the interactive prompt, you can load and use this function:
For absolute beginners (people who haven't run programming languages at all before, or did so from an environment that someone else set up and maintained), I suggest following the tips at the NLTK Getting Started page.
All (or nearly so) of the NLTK modules have demos. These provide an easy way to make sure that everything is installed correctly. Here's a sequence of commands that use modules we'll rely on throughout the course; start the Python interpreter and try pasting them in:
Now that the demos have all worked beautifully(?), let's try some code of our own.
Start the python interpreter and load the nltk WordNet lemmatizer:
Instantiate the lemmatizer for later use:
Test the lemmatizer. (The first argument is the string, and the second is a POS tag — values: a, n, r, v.)
To generalize this code a bit, open up an empty file in a text editor and paste in this code:
If you save this in a file (mine is in wordnet_functions.py), then you can import it into the interpreter and use it:
If all of the above worked out for you, then we can be pretty sure that you got Python, NLTK, and the NLTK data installed properly. If something went wrong, try to interpret the error messages you get back to determine what the problem is, and feel free to come to my office hours for trouble-shooting, debugging, and other techical woes.
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.