Figure MTURK
Experimental results suggesting that
texts reliably convey to readers which star rating the author
assigned.
This section uses words — here, (string, pos) pairs — gathered from a large online collection of informal texts to try to build lexical scales of a sort that could be used for calculating scalar conversational implicatures. We start by figuring out how best to study word distributions, then look at two methods (expected ratings and logistic regression) for assessing and summarizing those distributions and, in turn, for creating scales from them.
Associated reading:
Code and data:
The file imdb-words.csv consists of data gathered from the user-supplied reviews at the IMDB. I suggest that you take a moment right now to browse around the site a bit to get a feel for the nature of the reviews — their style, tone, and so forth.
The focus of this section is the relationship between the review authors' language and the star ratings they choose to assign, from the range 1-10 stars (with the exception of This is Spinal Tap, which goes to 11). Intuitively, the idea is that the author's chosen star rating affects, and is affected by, the text she produces. The star rating is a particular kind of high-level summary of the evaluative aspects of the review text, and thus we can use that high-level summary to get a grip on what's happening linguistically.
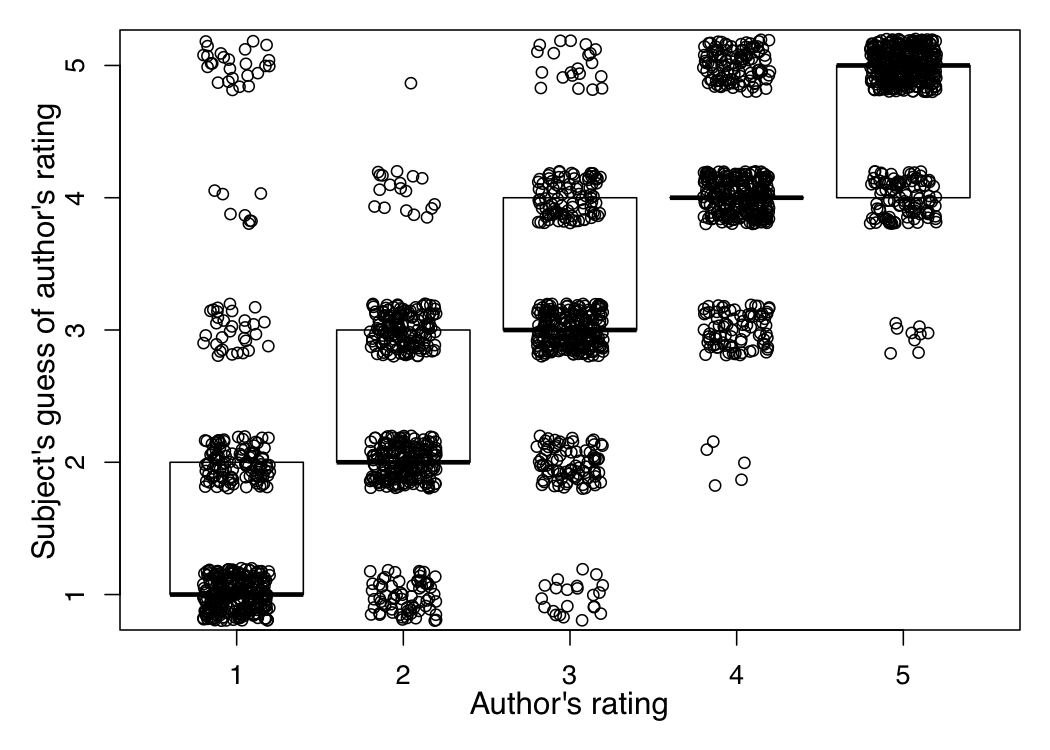
The star rating is primarily an indicator of the speaker/author vantage point. However, there is good reason to believe that readers/hearers are able to accurately recover the chosen star rating based on their reading of the text. Potts (2011) reports on an experiment conducted with Amazon's Mechanical Turk (Snow et al. (2008), Munro et al. (2011)) in which subjects were presented with 130-character reviews from OpenTable.com and asked to guess which rating the author of the text assigned (1-5 stars). Figure MTURK summarizes the results: the author's actual rating is on the x-axis, and the participants' guesses on the y-axis. The responses have been jittered around so that they don't lie atop each other. The plot also includes median responses (the black horizontal lines) and boxes surrounding 50% of the responses. The figure reveals that participants were able to guess with high accuracy which rating the author assigned; the median value is always the actual value, with nearly all subjects guessing within one star rating.
In creating imdb-words.csv, I took a number of steps to get as close as possible to a set of linguistically respectable word-like objects:
The column values for the file are as follows:
Since the file is in CSV (spreadsheet, tabular) format, it can be worked with using a variety of tools. This page uses R, for reasons discussed in the course overview.
First, move to the directory that contains the file and read it in:
The R head command displays the first n rows along with the header row. It's a useful way to make sure the data were read in correctly and to get a sense for the values (the first "word" in the file, (aa, n), is not especially word-like):
Before we look at any words in detail, it is important to get a sense for what the overall distribution of the data is like. As noted above, the Total column values are the same for all words, repeated only to make tabular processing easier. Let's look at just those values:
Eyeballing these values, one can see that they have a rough J-shape. Plotting the data makes this even clearer:
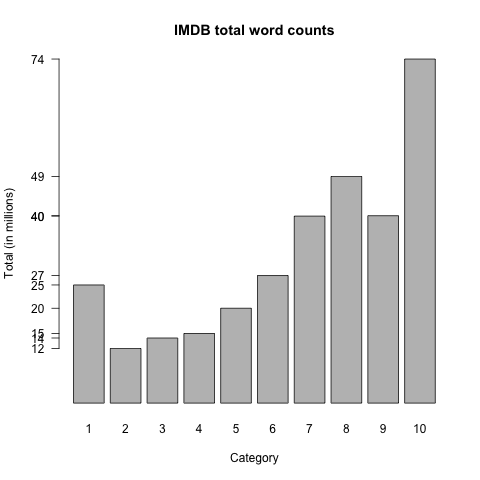
The total number of words represented is the row-count divided by 10, since each word gets ten rows. (If a word does not appear in a given Category, its Count value is 0 there.)
The Total values represent true token counts for the entire corpus. As discussed above, I did a lot of winnowing of the data to create this file, so the Count sums don't match the Total values in the way one might expect. Compare the following values with those of figure TOTALS:
This is really just a reminder that we're looking at a subset of the data. Happily, the category sizes for our subset are proportional to the full totals we are working with, as is evident from plotting the two sets of totals side-by-side in a barplot:

Thus, we could work with either set of values, I'd say. Our sample seems to be unbiased with regard to the nature of the categories. (This is not a foregone conclusion; we might have accidentially filtered off more 1-star words than 10-star ones, for example. It looks like this didn't happen, though.) I work with the Total values from here on out, for conceptual simplicity.
This section builds towards a preferred method for studying the distribution of words across the rating categories. I illustrate with (bad, a). Let's start by reading in its subframe and having a look at it:
As we saw above, the raw Count values are likely to be misleading due to the very large size imbalances among the categories. For example, there are more tokens of (bad, a) in 10-star reviews than in 2-star ones, which seems highly counter-intuitive. Plotting the values reveals that the Count distribution is very heavily influenced by the overall distribution of words:
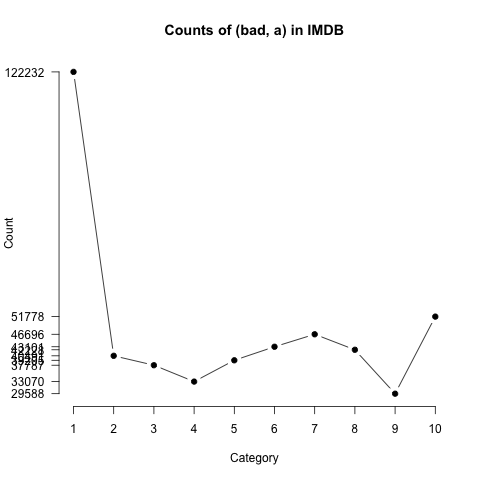
The source of this odd picture is clear: the 10-star category is 7 times bigger than the 1-star category, so the absolute counts do not necessarily reflect the rate of usage.
Before moving on to more useful measures, I want to pause to create a general function for plotting that is more useful than the defaults provided by R. In particular, I would like to follow the advice of Tufte (2006): the axis labels will be actual values from the data, displayed intuitively:
Using this function, you can recreate the left panel in figure COUNTS:
To get relative frequency values, we divide the Count values by the corresponding Total values. The following command adds these values as the rightmost column in our bad subframe:
Relative frequency values are hard to get a grip on intuitively because they are so small. Plotting helps bring out the relationships between the values:

RelFreq values seem to bring out important usage patterns. The imbalances in the size of the underlying categories seem to have disappeared. (However, see Baayen 2001 for detailed disussion of how corpus size can affect word distributions, though most of the concerns relate to vocabulary size.)
One drawback to RelFreq values is that they are highly sensitive to overall frequency. For example, (bad, a) is significantly more frequent than (horrible, a), which means that the RelFreq values for the two words are hard to directly compare. The following code attempts to do that, by putting them side-by-side and stretching the y-axis enough to include all of the values for both of them:
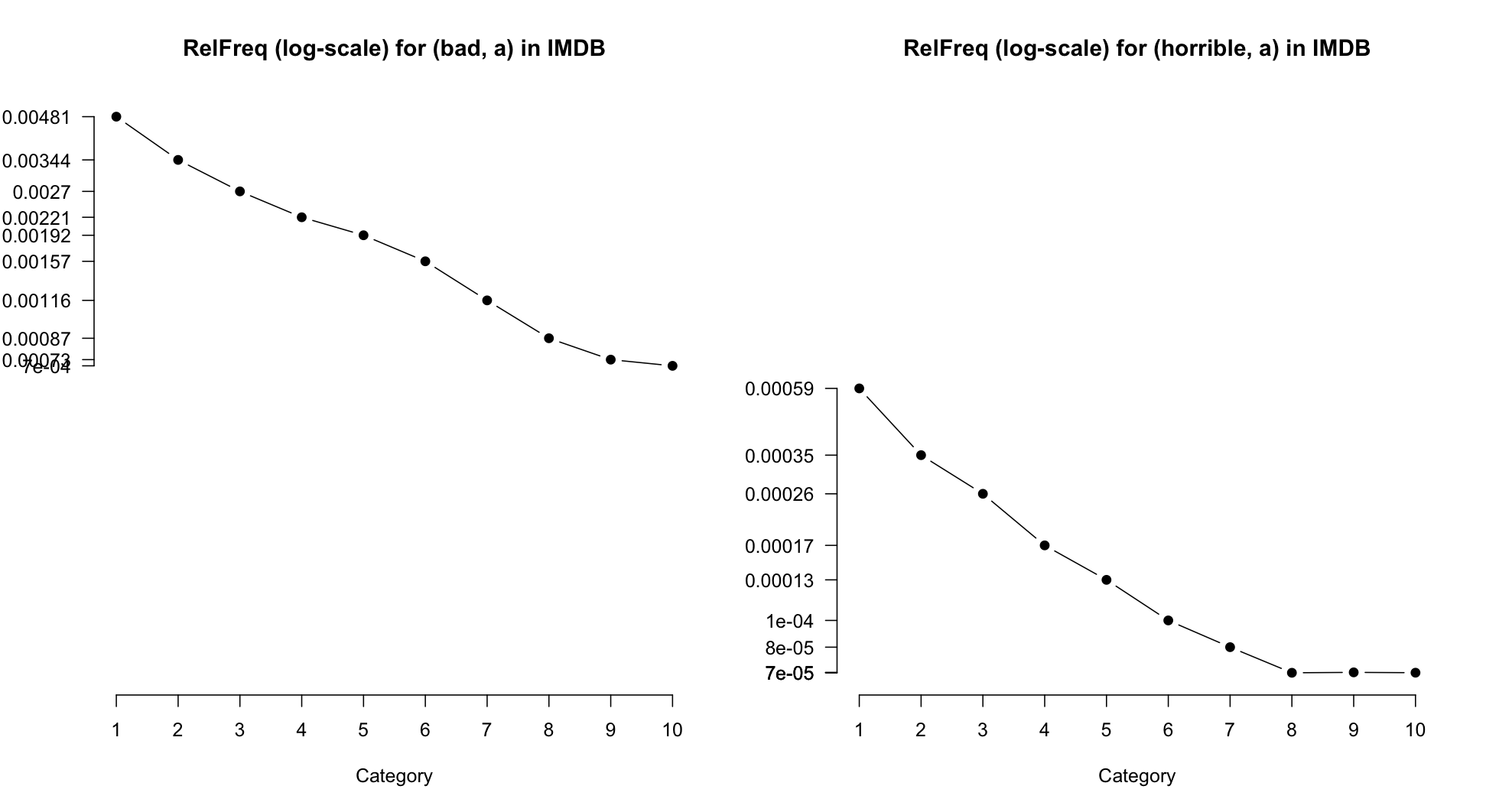
It is, I think, possible to discern that (bad, a) is less extreme in its negativity than (horrible, a). However, the effect looks subtle. The next measure we look at abstracts away from overall frequency, which facilitates this kind of direct comparison.
A drawback to RelFreq values, at least for present purposes, is that they are extremely sensitive to the overall frequency of the word in question. There is a comparable value that is insensitive to this quantity:
Pr values are just rescaled RelFreq values: we divide by a constant to get from RelFreq to Pr. As a result, the distributions have exactly the same shape; compare the following with figure RELFREQ:
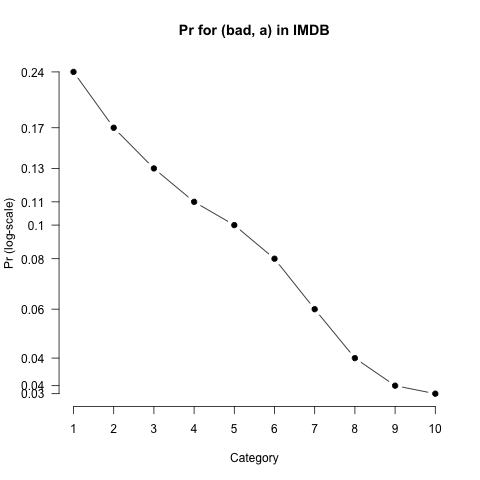
A technical note: The move from RelFreq to Pr actually involves an application of Bayes Rule.
Pr values greatly facilitate comparisons between words:
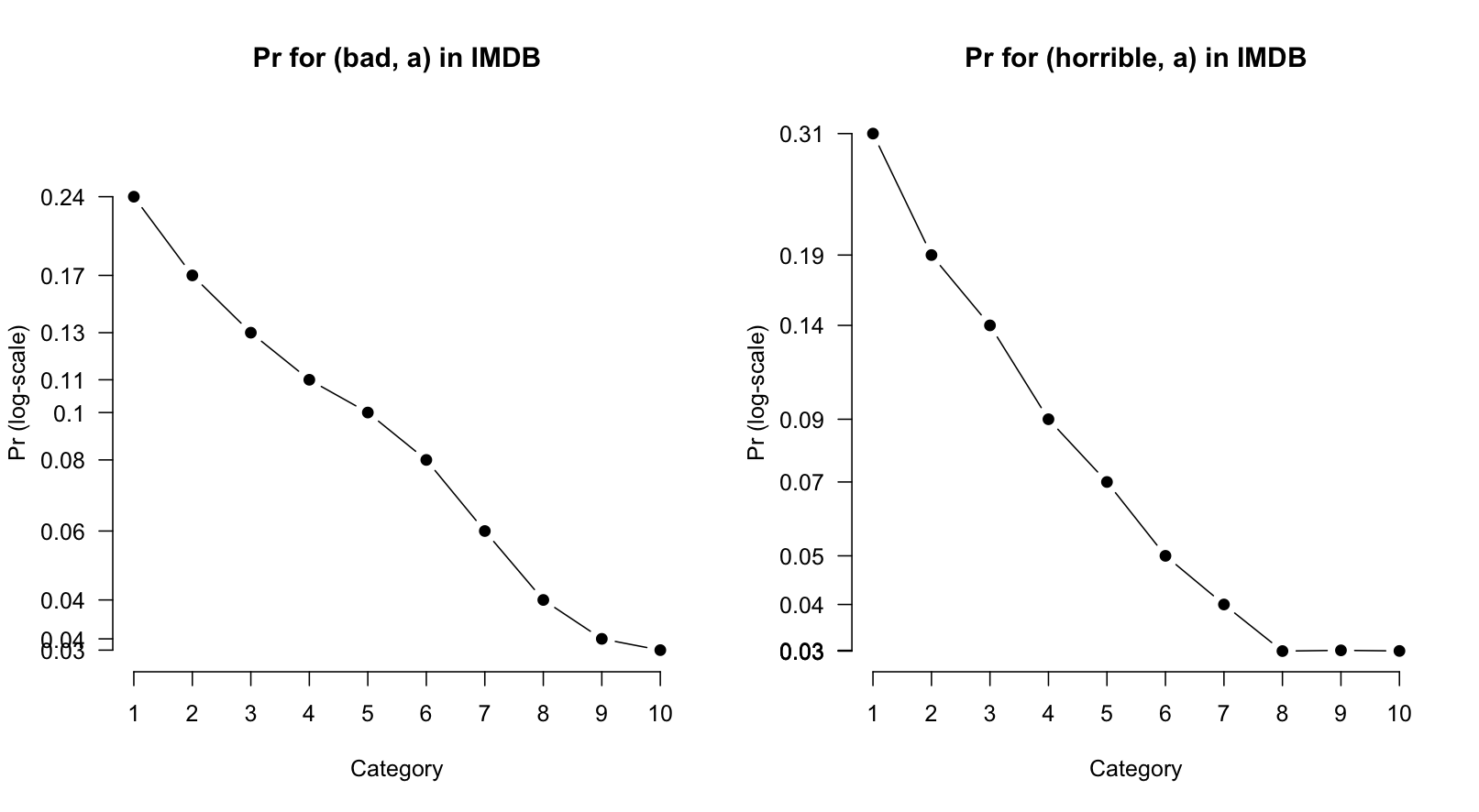
I think these plots clearly convey that (bad, a) is less intensely negative than (horrible, a). For example, whereas (bad, a) is at least used throughout the scale, even at the top, (horrible, a) is effectively never used at the top of the scale.
It's useful to pause at this point to generalize the process of grabbing a word's phrase frame and adding RelFreq and Pr values:
This section develops two methods for studying the distributions more closely, moving beyond impressions based on plots to get at some more objective measures of what the distributions are like and how confident we can be that they meaningfully reflect usage patterns (as opposed to being just quirks traceable to low overall frequency, quirks in the data, etc.).
Expected ratings calculations are used by de Marneffe et al. 2010 to summarize Pr-based distributions. The expected rating calculation is just a weighted average of Pr values.
To get a feel for these values, it helps to work through a couple examples. In the first, we assume that 100% of the tokens of the word in question are in the 10 star review:
In the next example, we add some tokens to the middle of the scale:
The following code adds the ER value to our plots (bad, a) Pr plot:
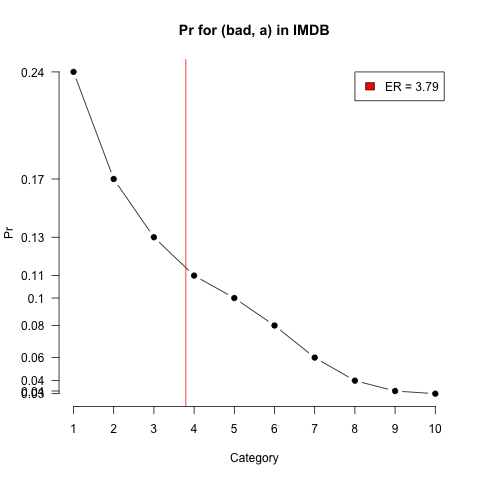
We will use expected ratings later, as one method for building scales, so here is a general utility for creating them from a word's phrase frame:
Expected ratings are easy to calculate and quite intuitive, but it is hard to know how confident we can be in them, because they are insensitive to the amount and kind of data that went into them. Suppose the ER for words v and w are both 10, but we have 500 tokens of v and just 10 tokens of w. This suggests that we can have a high degree of confidence in our ER for v, but not for w. However, ER values don't encode this uncertainty, nor is there an obvious way to capture it.
Logistic regression provides a useful way to do the work of ERs but with the added benefits of having a model and associated test statistics and measures of confidence. For our purposes, we can stick to a simple model that uses Category values to predict word usage. The intuition here is just the one that we have been working with so far: the star-ratings are correlated with the usage of some words. For a word like (bad, a), the correlation is negative: usage drops as the ratings get higher. For a word like (amazing, a), the correlation is positive. (You can check this quickly using WordFrame to build the frame and WordPlot to plot the associated RelFreq or Pr values.)
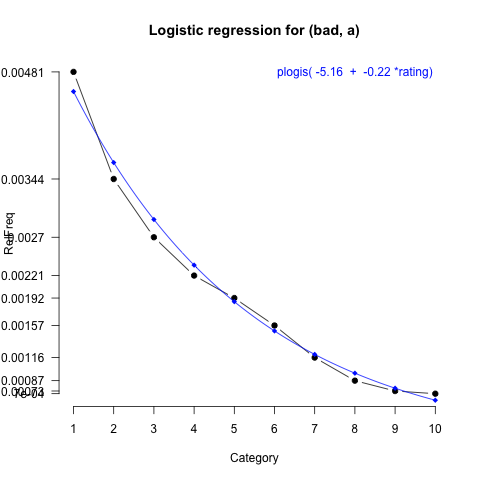
With our logistic regression models, we will essentially fit lines through our RelFreq data points, just as one would with a linear regression involving one predictor. However, the logistic regression model fits these values in log-odds space and uses the inverse logit function (plogis in R) to ensure that all the predicted values lie in [0,1], i.e., that they are all true probability values. Unfortunately, there is not enough time to go into much more detail about the nature of this kind of modelling. I refer to Gelman and Hill 2008, §5-6 for an accessible, empirically-driven overview. Instead, let's simply fit a model and try to build up intuitions about what it does and says:
Here, we use R's glm (generalized linear model) function to predict log-odds values based on Category. The expression cbind(bad$Count, bad$Total-bad$Count) is used internally by glm to derive the log-odds distribution. Category is our usual vector star ratings.
Let's begin by inspecting the coefficients for this fit:
We can also plot the model in log-odds space:

It also helps intuitions to calculate some sample values and compare them to the empirical log-odds that we added to the frame.
Log-odds values are notoriously hard to interpret. It is more intuitive to think about what is happening in probability space. To do this, we apply the inverse logit function to the model estimates:
R actually provides these fitted values. The default way they display isn't great (try badFit$fitted), so let's add them directly to our frame:
Let's put all this together into the most information rich, intuitive plot we can muster:
There is one more ingredient to add: p-values. To see the p-values for the model:
These provide us with an estimate of how much confidence we can have in our model. You can extract them from the above table with summary(badFit)$coef[1,4] (for the intercept) and summary(badFit)$coef[2,4] (for the Category coefficient). We aren't concerned here with the Intercept value, so let's define a function that extracts the Category p-value and also delivers it in a format suitable for printing:
To round out this section, let's define a general method for fitting our simple logistic regression:
We would like a function that allows us to visualize the Pr values of words really quickly, given one of the data sets:
To close some comparisons that help to bring out how the coefficients and p-values might be useful as a filter:

exercise DISPLAY, exercise SALT, exercie QUAD
We can use the ER and logistic regression values to order all the lexical items. First, let's create a separate table containing just the ER value, Category coefficient, and Category p value for each word in the vocabulary. To do this efficiently, I first define an auxiliary function that, given a word's frame, gets these values for us:
The function ddply from the plyr library efficiently handles grouping words (based on Word–Tag identity) and sending those subframes to WordAssess for the needed values, then adding them to a data.frame:
It will take your computer a long time to generate the ER values for either of these large files. For safety, save to a file so that you can use it later:
Here's a link to my version of this assessment file:
Only a small percentage of the words in the vocabulary meet the 0.001 significance threshold:
The coefficient values and ERs are intimately related:
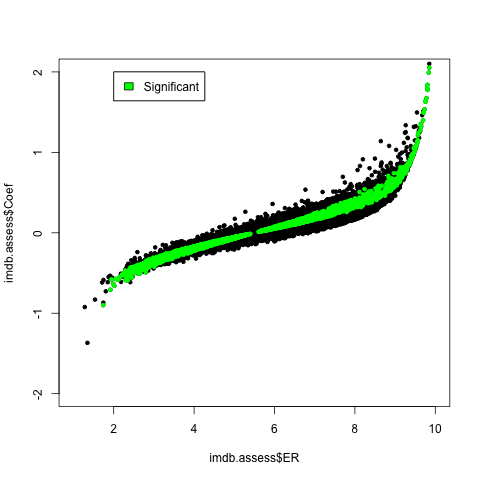
The significant subset seems of most interest, since we can count on its estimates more. A first thing to notice about it is that its distribution relative to categories is different from that of the larger population, presumably because some categories are more scalar, in the requisite sense, than others.
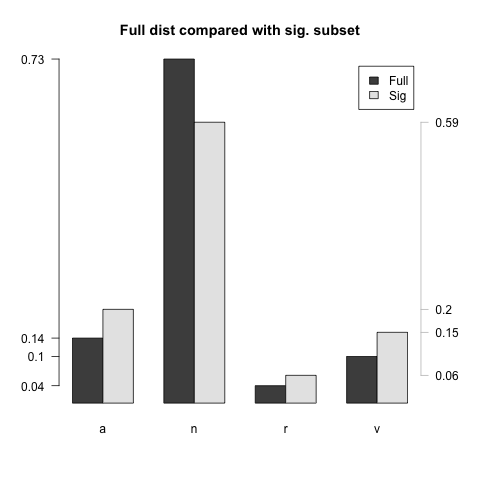
Since scalar comparisons are likely to be between items of the same category, it seems smart to limit attention to specific categories. Let's check out the adjectives, which have poor coverage in the WordNet hierarchy:
These lists look pretty good. There is some influence of the underlying domain, but that could perhaps be weeded out via other resources. See the exercises for more on that.
REVIEWLEVEL The following data-frame gives some review-level information for the IMDB corpus:
Read it in and then: (i) create a barplot of the review sizes, (ii) create a percentage-wise barplot that gives the review counts and the word counts side-by-side, and (iii) plot the average word counts relative to the categories. For each plot, give the commands you used as well as a few sentences summarizing what useful conclusions we might draw from the plots (things we might keep in mind when doing analysis.
PREX In creating the Pr estimates, I applied Bayes Rule under the assumption of a uniform prior. What happens if we include the prior information? For this, you can use the following counts of reviews to calculate Pr(rating), the probabilities for the rating categories. (This problem can be done with supplementary R code, or just in prose and math.)
REGEX It's often useful to be able to group words by regular expression. The following function will do this, using grepl:
Modify and extend WordFrame so that the user can add the optional keyword argument regex=TRUE and search by regular expression instead of string. (The only trick here is that the corresponding Count values should be added, which can easily be done with xtabs, but the Tag and Total values should not be added, since they are constant across different strings.)
(While you are at it, you might like to allow regexs over the Tag value as well. The technique is the same; perhaps one wants wordRegex=TRUE/FALSE and tagRegex=TRUE/FALSE to control the behavior.)
DISPLAY Explore a few other words using WordDisplay, to get a feel for what the data are like. Then pick a handful of words and state your expectations for what their profiles should be like and how they should compare. Then issue the command par(mfrow=c(1,wc)) where wc is the number of words to compare, following by WordDisplay commands for each of the words. To what extent are your expectations born out?
SALT The files imdb-unigrams.csv and fivestarreviews-unigrams.csv in the archive potts-salt20-data-and-code.zip have the same basic structure as imdb-words.csv except that they lack tag information. (They are much bigger, though.) Adjust the plotting and analysis functions given above so that the Tag argument is optional and, if not given, ignored. Then perhaps try out some analysis with these larger data sets.
QUAD Use WordDisplay to plot (absolutely, r), (totally, r), and (ever, r). The values that we've derived seem problematic. How? One way to correct this is to build a second kind of logit model, this one with a component that squares the rating value. (For details, see Potts and Schwarz 2009.) Write a function for fitting such models and diplaying them. (It might be nice to allow users of WordDisplay to pick which kind of model they want to fit, via a keyword argument.)
IQAP (This problem pairs well with the corresponding one for WordNet.) Recall that the iqap.Item methods question_contrast_pred_trees() and answer_contrast_pred_trees() extract the subtrees rooted at -CONTRAST nodes from the questions and answers. If we are going to use the review data to compare these trees, then we should first get a sense for how well they cover the IQAP data. As a first step towards doing this, the following code loops through the development set of the IQAP corpus, pulling just the items that have a single '-CONTRAST' word in both the question and the answer. Finish this code so that it provides an assessment of the coverage.
SENTI This exercise from the WordNet section maps the SentiWordNet scores to a CSV file. Compare those scores with those of imdb-assess.csv (ER values or Coef values, with or without using the p-value as a threshold.). How do the two resources compare? Do they seem to provide conflicting, complementary, and/or correlated information? Which seems more useful and/or more accurate?
WORDCMP Figure BHPR informally compares (bad, a) and (horrible, a). The visual impression is that (horrible, a) is the more strongly negative of the pair: it is used hardly at all in the most positive categories, and then begins a very steep rise to 1 star. The trend for (bad, a) is similar, but its inverse correlation with the ratings is more moderate.
We would like to make these comparisons more rigorous, with a defined method and some assessment of confidence in the contrasts we think we've found. Intuitively, we would like to compare the logistic regression fits to see whether their coefficients for rating are significantly different. Propose a method for doing that and illustrate how it works for (bad, a) and (horrible, a).
Reveal/Hide a partial solution
Davis (2011: 222ff) develops a technique for comparing whether one logistic regression fit is reliably different form another. I illustrate his technique by way of (bad, a) and (horrible, a).
Step 1: Get the data.frame and add a column distinguishing the two words:
Step 2: Fit a logistic regression using Category and stronger as interacting predictors:
Step 3: View and interpret the results:
The interaction term Category:strongerTRUE says that strongerTRUE correlates negatively with Category (rating). That is, where the word is (horrible, a), we have an increase in the inverse correlation seen in the negative value for the Category coefficient. The negative coefficient for strongerTRUE just reflects the fact that (bad, a) is much more frequent than (horrible, a).
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.