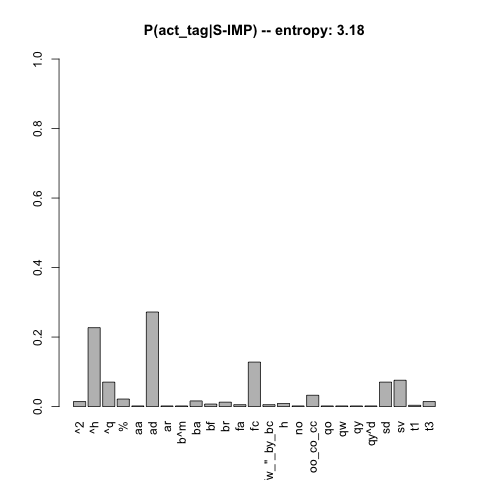
Figure IMP
The distribution of DAMSL act tags for
trees rooted at S-IMP. The barplot depicts only non-0 values above the
25th percentile. The entropy calculation is for the entire distribution.
To what extent is dialog act predictable from clause typing? I explore this question with a narrow focus on question acts and polar interrogative clause types. In the context of the SwDa, this boils down to the relationship between the dialog-act tag 'qy' and polar interrogative clausal forms. Most of the work involves homing in on what thise clausal forms are actually like.
Code and data:
This section looks at the q-type tags that are likely to be confusable with qy. To keep the discussion streamlined, I leave the following tags aside:
Searching the section numbers is an easy way to find the descriptions in the Coders' Manual.
DAMSL group: qy, qy^g, qy^t, qy^r, qy^h, qy^g^t, qy^m, qy^c, qy^2, qy(^q), qy^g^r, qy^g^c, qy^c^r
The Coders' Manual for the SwDA suggests that we can simply assume that 'qy', as a dialog act, will correspond to an inverted polar interrogative clause:
qy is used for yes-no questions only if they both have the pragmatic force of a yes-no-question *and* if they have the syntactic and prosodic markings of a yes-no question (i.e. subject-inversion, question intonation).
qy B.82 utt1: Do you have to have any special training? / qy A.1 utt1: Do you know anyone that, {F uh, }[ is, + is ] in a qy A.1 utt1: Okay, {F um, } Chuck, do you have any pets # there at your home? # / qy B.28 utt1: Does he bite her enough to draw blood? / qy B.48 utt1: Is that the only pet that you have? / qy A.55 utt2: {D So } have you tried any other pets? / qy A.96 utt3: Do you? /Yes-no questions that are pragmatically questions but have declarative syntax are marked with ^d. Yes-no questions that are syntactically (in form) questions but do not rhetorically function as questions ("rhetorical questions") are marked either as qh or bh, depending on whether the rhetorical question is functioning as a backchannel. See the other sections for examples of each of these other kinds of "questions".
However, the following note in the section on declarative questions indicates that there are going to be problems with a syntactic selection method that depends on the canonical inverted form for polar interrogatives.
However, if the statement has an "ellipsed" aux-inversion at the beginning, we don't code it as a declarative question (following Weber 1993).
qy B.44 utt1: Worried that they're not going to get enough attention? /
DAMSL group: qr, qr^d, qr^t, qr(^q)
Coder's Heuristics
examples:
qr B.50 utt1: {D Well, } do you live, [ [ you, + you ] + ] in a house, or a place where you, {F uh, } -/ qr B.95 utt1: # {D Well } # do you all work for T I, or for, -/ qr B.36 utt1: # {D Now, } # [ are they, + are they ] rehabilitative [ or, + or ] not. /One problem with or-questions is that the listener often interrupts before the or clause is complete and answers the or-question as if it were a yes-no question about the first clause. For example
qr B60 utt1: Did you bring him to a doggy obedience school or -- nn A61 utt1: No -- / + B62 utt1: -- just -- sd^e A63 utt1: -- we never did. / + B64 utt1: -- train him on your own /We counting this as a qr since the speaker goes on to finish his qr, even though the listener answers it immediately as a yes-no question. Our current viewpoint is that if there's a conflict between labeling "what the speaker thinks" and "what the hearer thinks" go with whichever coding is more informative for the reader, which in this case is the speaker-labelling (because if you were reading the transcript you could figure out that a qr followed by a "No" answer means that the listener misinterpreted. But if you labeled it the other way (i.e. as a "qy") then it would be harder to figure out that the speaker was thinking of the utterance as an or-question.
DAMSL group: qrr, qrr^t, qrr^d
Coder's Heuristics
These are used when you think the speaker tacked on an or-clause to what had been a yes-no question, so "qrr" marks a sort of "dangling or-clause", e.g. B.18.utt2.
qy B.18 utt1: # [ Do you watch, + # do you watch ] [ the network, + {D like } major network ] news, / qrr B.18 utt2: {C or } do you watch {D like } -- sd A.19 utt1: [ Just the # regular channel # -- + + B.20 utt1: -- # the MACNEIL LEHRER HOUR? # / sd A.21 utt1: -- just channel eight. ] /When the speaker uses the word "or" after a qyin a slash-unit by itself at the end of a turn, it is coded as a turn-exit (i.e. %):
qy* B.64 utt1: {F Uh, } is that the crime / [[*listen]] qy B.64 utt2: {C and } it's already, (( )) some chart and determine the punishment, / % B.64 utt3: {C or. } -/
DAMSL group: ^d, ^d^t, ^d^r, ^d^m, ^d^t, ^d^h, ^d^c, ^d(^q)
These labels are in an independent dimension from the other question labels (qy,qw,qo,qr,qrr). Like some of the other SWBD-DAMSL "extra dimensions", these are primarily designed to code form.
Declarative questions (^d) are utterances which function pragmatically as questions but which do not have "question form". We don't know if declarative questions will have different conversational function than non-declarative question (although see Weber 1993 for thoughts on this), but we definitely expect them to be useful for ASR language-model purposes.
Declarative questions normally have no wh-word as the argument of the verb (except in "echo-question" format), and have "declarative" word order in which the subject precedes the verb. See Webber 1993 Chapter 4 for a survey of declarative question and their various realizations.
Declarative questions *may* have rising "question-intonation". The "declarative" tag is added solely based on form. This does not mean that the intonation of the question is irrelevant. We are marking the prosodic features of each utterance in Switchboard in another, distinct database.
Coder's Heuristics
These are all ^d (declarative questions): (B.46.utt1 is an example of a declarative question with a wh-word)
qy^d B.44 utt1: <Laughter> {D So } you're taking a government course? / qw^d B.46 utt1: At what? / qy^d B.46 utt2: The university? / qw^d B.22 utt1: [ {C And, } + {C and } ] you say you've had him how long? / qy^d A.1 utt3: I don't know if you are familiar with that./ qy^d A.3 utt1: {C But } not for petty theft? qy^d A.65 utt1: {D Well, } I guess we'll get pretty good news coverage in a couple of years when you host the, { F uh, } summer olympics <laughter>. /Or the following:
qy^d B.2 utt2: You're asking what my opinion about, ny A.3 utt1: # Yeah. # / + @B.4 utt1: # whether it's # possible <laughter> to have honesty in government. /Or here's another one:
qy^d A.64 utt2: you must be a T I employee. /However, if the statement has an "ellipsed" aux-inversion at the beginning, we don't code it as a declarative question (following Weber 1993).
qy B.44 utt1: Worried that they're not going to get enough attention? /
DAMSL group: ^g, ^g^t, ^g^r, ^g^c
A 'tag' question consists of a statement and a 'tag' which seeks confirmation of the statement. Because the tag gives the statement the force of a question, the tag question is coded 'qy^g'. The tag may also be transcribed as a separate slash unit, in which case it is coded '^g'.
Coder's Heuristics
A question designed to check whether the listener understands what the speaker's point is should be distinguished from a question tag. Listener may respond affirmatively that s/he understands what was said without implying agreement. "understand what I'm saying" and thus respond affirmatively to an 'understanding check' but disagree with speaker's statement. The appropriate response to a tag question, on the other hand, confirms the *statement*.
The appropriate code for an understanding check is "qy"
The appropriate code for the response, like the response to a tag question, is usually ny or nn. The appropriate response to an understanding check is also 'ny' or 'nn.
In answering a true tag, you are confirming or disconfirming the statement that precedes it.
In answering a question about 'understanding-check', listener is not taking any position on the statement that preceded it. S/He is merely indicating that the statement was understood.
Tag questions all have either an aux-inversion at the end (don't you? doesn't it? isn't he? aren't you?) which (almost always) reverses the polarity of the auxiliary in the matrix statement, or a one-word tag like ", right?" or ", huh?".
Here are some examples of ^g (tag questions): single-word tag:
qy^g A.39 utt2: {F Uh, } I guess a year ago you're probably watching C N N a lot, right? /unreversed polarity, with subject-aux inverted tag:
qy^g@ @B: {D So } you live in Utah do you? /reversed polarity, with subject-aux inverted tag:
qy^g A.27 utt1: That's a problem, isn't it? / qy^g B.54 utt1: # {C But } that doesn't eliminate it, does it? # /tag in single slash unit:
sd A.1 utt 1: Well, Hank Williams is one we forgot about. / ^g A.2 utt 2: Right? / __________ sd A.13 utt2: as a matter of fact, I want to think they took the top managers first, / ^g A.13 utt3: isn't that a fact? /
SQ root nodes roughly pick out polar interrogative clause types. Some of them have extensions like -CLF (Was it Sue... and Who was it ...) and -UNF (a clause that the speaker did not finish). Our first step in identifying polar interrogative matrix clauses is to define a function that selects these AQ trees:
This will collect polar interrogatives. It excludes constituent questions because they have 'SBARQ' as their root node, with an embedded SQ:
However, root-level SQ labels a lot of structures that do not involve inversion. For example, all tag questions have this as their root label:
It also captures cases where there is no inversion. Some of these are declarative questions that we want to exclude:
To address this, I define a function has_leftmost_aux_daughter(tree) that tries to identify clauses with auxiliary verb daughters that are to the left of any nominal or sentential nodes (signaling inversion but ignoring disfluencies, interjections, adverbial clauses, etc.):
This leads to the proposal for characterizing polar interrogatives syntactically:
And now an informal inspection, limiting attention to the utterances that have a single tree that corresponds perfectly to the utterance text. More precisely, the function classifies trees and keep a random sample of 100 yes's and 100 no's for us to inspect.
The evaulation is then done as follows:
The results are encouraging, broadly speaking. The list of 'True' responses looks to be high precision, capturing even difficult looking cases like:
However, there is a worrisome pattern in the 'False' list: lots of apparently ellipitical interrogatives like these:
Nonetheless, let's assume that we have the ability, with is_polar_interrogative(tree), to identify polar interrogative trees. The next step is to make sure we understand what things get labeled qy.
exercise MOD, exercise ELLIPTICAL
The experiment simply involves gathering data on the relationship between the act-tag 'qy' and the values returned by is_polar_interrogative(tree). The following function puts all these pairs into a CSV file so that we can study and visualize the patterns in R:
The resulting file:
Now over in R, we read in the CSV file and check out the confusion matrix:
This looks good, and it's of course initially very satisfying to look at overall accuracy:
Whoa! Nearly perfect! However, this is a poor assessment figure in this context, because the (FALSE, FALSE) corner of the confusion matrix is so massive. Consider, for example, the right column of the confusion matrix. It says that 1497 of the clauses we identfied are in fact 'qy' acts. However, in order to achieve this high number, we had to guess wrong 710 times, a fairly substantial part of the total. Intuitively, our precision is low. Formally, a system's precision for a category C is defined as the number of true-positives for C divided by the total number of times that the system guessed C. Here are the relevant calculations for the 'qy' and non-'qy' categories:
Precision for the the non-'qy' category remains high. We do indeed do very well there. It's much more modest for the smaller 'qy' category, though.
A system can achieve perfect precision for a category C by never guessing it. For this reason, precision is generally paired with recall, which, for a category C, assesses the number of C-type things that the system identifies, balancing that against the total number of C-type things. Thus, now we calculate row-wise in the confusion matrix:
Once again the 'qy' category is the worrisome one.
We want to get to the bottom of this. That's what the discussion section below is all about. However, it's nice to round to round out this section with a bit of statistical evidence we have found a true association between clause-type and dialog act — a quick chi-squared test on the matrix:
Now let's figure out what's going on with the mis-alignments.
| Tag | Gloss | Freq | |
|---|---|---|---|
| 1 | bh | rhetorical question continuer | 205 |
| 2 | % | indeterminate, abandoned | 118 |
| 3 | qrr | or-clause (or is it more of a company?) | 78 |
| 4 | qr | alternative (`or') question | 64 |
| 5 | qh | rhetorical question | 45 |
| 6 | qy^t | qy + "about the task" | 32 |
| 7 | qy^d | declarative question | 19 |
| 8 | sd | statement non-opinion | 14 |
| 9 | b | acknowledge (backchannel) | 13 |
| 10 | ba | appreciation | 13 |
| 11 | sv | statement opinion | 13 |
| 12 | ^q | quotation | 12 |
| 13 | qy^r | qy + repeated | 9 |
| 14 | ad | action directive | 7 |
| 15 | qy^c | qy + about communication | 7 |
| 16 | fc | conventional closing | 6 |
| 17 | qo | open-ended question | 6 |
| 18 | aa | accept | 5 |
| 19 | ^g | tag-question | 4 |
| 20 | qrr^t | qrr + "about the task" | 3 |
| 21 | qy^g | qy + tag question | 3 |
| 22 | qy^h | qy + "let me think"-style hold | 3 |
Some of these mistakes are forgivable. For example a qy^t (question about the task) is still a qy, as is qy^r (repeated question). This is arguably true of qrr (or-initial question) and qy^h (question with request for a moment to think).
Other mistakes are not forgiveable, but they are informative. For example, the overall syntactic structure is not revealing of whether a question is rhetorical or not, and this is the largest source of errors, with bh + qh accounting for 256 mistakes.
We could get some mileage out of reaching down into the structure to try to detect whether the question is an 'or' question or not.
To understand the false negatives, we need to inspect the trees themselves. The following function returns a randomly selected subset of the false positive trees and writes them to a file called 'swda-clausetyping-fp-trees.txt'.
I ran this function and then hand-annotated the output, which you can check out here:
I found the breakdown of error types given in table FN. The "Declarative forms with visible auxs" are the ones that have haunted us throughout the investigation. The high number of "Declarative forms with visible auxs" is surprising, since those have the form of rising declaratives but were judged not to serve the special rhetorical function associated with those clauses.
| Error type | Count |
|---|---|
| Declarative forms with visible auxs | 21 |
| Ellipitical forms | 15 |
| Fragments of various kinds | 11 |
| wh interrogatives | 2 |
| Unanticipated EDITED node structure | 1 |
This section introduces a method for seeking out other areas in which it seems fruitful to study the associations between form (syntax) and function (pragmatics).
My basic strategy is to use the root nodes of the Penn Treebank parses as rough approximations of their clause-types, relating them to act tags in various ways.
The following Python function builds a CSV file whose rows are (ActTag, DAMSL Act Tag, Root Label) trios. This will be the basis for the exploration.
Here's a direct link to the resulting file:
From here on, we'll work with the file in R:
Table ROOTS provides the full set of root nodes in the SwDA parses with their counts (restricting attention to utterances for which tree_is_perfect_match() == True); this table was created with the following commands:
|
|
The first perspective I take is a hearer perspective in the following sense: it says given that I heard/parsed clause-type C, what are the probabilities of various act tags (pragmatic functions) that the speaker might have intended?
For example, the following code builds such a distribution for the root node S-IMP (imperative):
This distribution is very hard to plot, because there are so many values for the tags. The visualizations become more readable if we restriction attention to just the values that are above the 25th percentile, first filtering off the 0-valued elements:
Figure IMP plots this distribution. I've also added the entropy of the entire (un-filtered) distribution, as a summary measure of its diversity. This value was calculated with GeneralizedResponseEntropy() using the original counts vector.
The function TagGivenLabel() inside swda_functions.R generalizes this code: the user supplies a regular expression over root labels and the function handles the rest. Thus, generating the above plot is as simple as this:
Because the second argument is a regular expression, one can also pool different root-labels:
The speaker perspective turns around the hearer distribution P(tag|clause-type). That is, we want to study P(clause-type|tag). The idea is that the hearer decides what pragmatic move to make and then, given that decision, has a choice about which clause-type to use to express it.
The process is exactly the same as the one we used above, except here we begin by picking a tag and then look at the distribution of root-nodes for that tag. In my illustration, I choose 'ad' (action directive).
I filter the distribution in the same way, again to improve readability:
Figure AD plots the filtered distribution and also provides the entropy of the entire distribution:

The function LabelGivenTag() inside swda_functions.R generalizes this code: the user supplies a regular expression over DAMSL act tags and the function handles the rest. Thus, generating the above plot is as simple as this:
As with TagGivenLabel, the regular expression interface allows you to pool groups of tags.
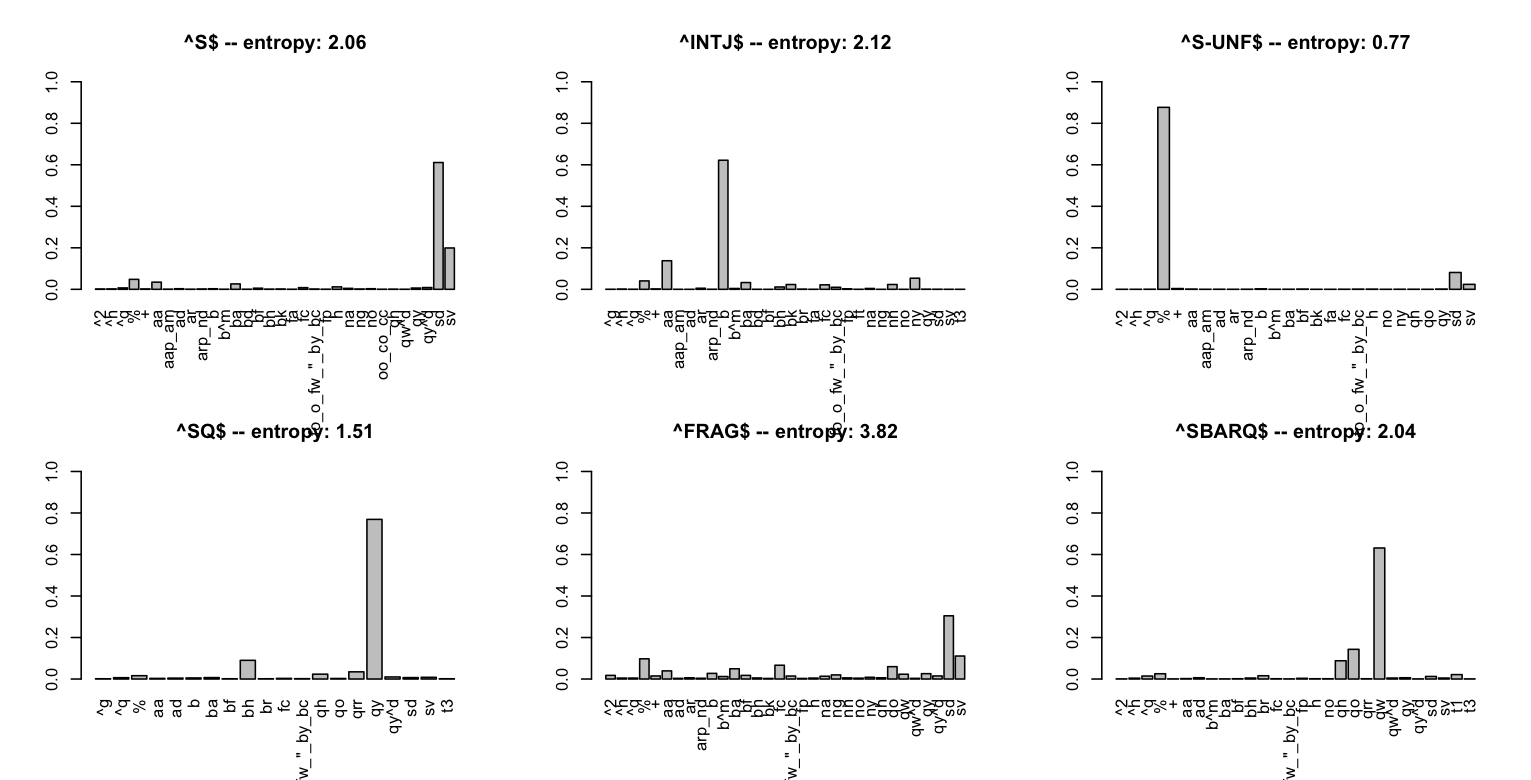
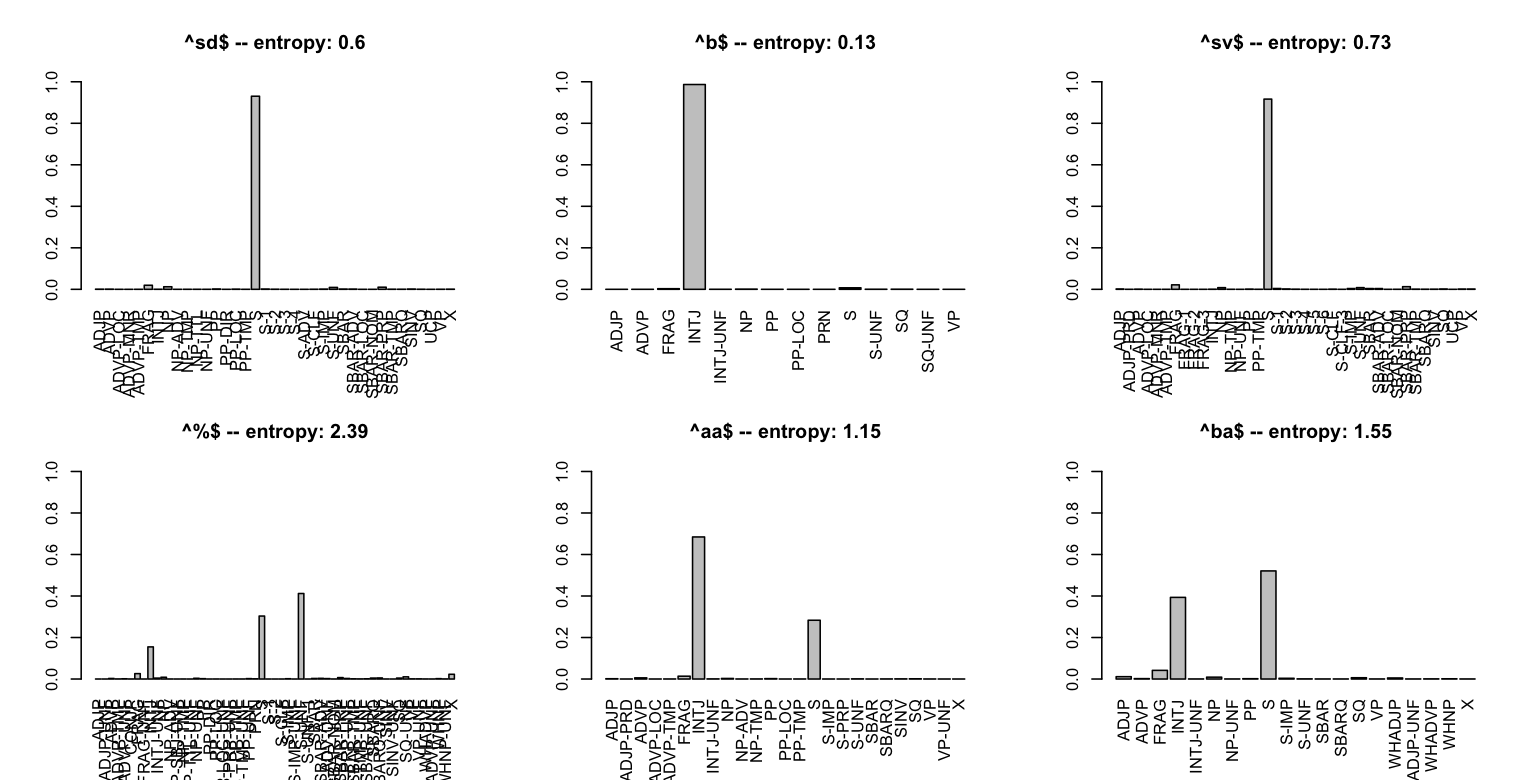
The file swda_functions.R also contains functions LabelGivenTagPlots() and TagGivenLabelPlots(). The first argument to each is the full dataframe derived from swda-actags-and-rootlabels.csv (our df above) and the second is an integer n (default: 10). The functions then display information for the n most frequent root nodes (DAMSL act tags). Figure ROOTDISTS and Figure TAGDISTS give the output of these functions for n=6.
DAMSL The DAMSL act simplifications for questions are pretty aggressive. I am concerned in particular about the fact that it reduces qy^g to qy. What impact might this have on our experiment? You can answer this question by relying on the samples from the Coders' Manual, or you can write code to study these tags more systematically. (Note: inspect_trees() will return a sample for any Tree-to-booleans function you write.)
RHETORICAL Using the corpus or your own intuitions, identify 3-5 morphosyntactic features that could be used to distinguish rhetorical questions from regular questions. (These could be heuristics; I think you won't find any deterministic features for this.)
MOD Our theory of the form of polar interrogatives is embodied in is_polar_interrogative(). Modify or completely rewrite that function and then evaluate it using inspect_trees(). Summarize how well your function does, perhaps contrasting its strengths and weaknesses with those of is_polar_interrogative.
ELLIPTICAL Elliptical forms like You going? are misdiagnosed by our function because they return False. We might be able to catch them by looking for VP nodes that lack an aux daughter but do have a 'VBG' (gerund) or 'VPN' (participle) daughter. Write a function does seeks to identify such configurations. (Feel free to improve on the technique as well.)
TAGS It seems that tag questions are structures with SQ roots that have SQ daughter nodes. Is this characterization correct? Write a function that identifies such structures and use inspect_trees() to assess it.
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.