
Figure FITS
A graphical illustration of how to use a fitted
model (the one from the prose) to classify examples.
In this section, we return to the IQAP corpus, bringing together the information we extracted from WordNet and the IMDB reviews to try to enrich the IQAP answers. I begin with a deterministic enrichment strategy and then move to a probabilistic model.
Throughout this section, I work with a binary version of the ratings: 'definite-yes' and 'probable-yes' collapse to 'yes', and 'definite-no' and 'probable-no' collapse to 'no'. This makes the experiments conceptually simpler, and it side-steps my current lack of understanding of how the 'probable' categories were used.
In iqap.Item, the methods response_counts, response_dist, and max_label all have an optional keyword argument make_binary which peforms this category collapse if set to True.
In R, one can achieve the collapse by adding column values:
Code and data:
To rerun the experiments, head to the bottom of the iqap_experiments.py, where you will see options for running either the series of deterministic experiments or the probabilistic one.
The first experiment is deterministic in the following sense: we work towards defining a single function that predicts 'yes' or 'no' as the label for each Item.
To prevent mistyping, and to allow flexibility, I define two global Python variables for specifying predictions:
To begin, we look at cases where both the question and the answer have just one word in their '-CONTRAST' sets, which means that we can compare the two words directly using the resources we've developed.
The following function allows us to move quickly to just these 'one-worders'; using this will simplify a lot of our code.
The following is a WordNet prediction function. It uses wordnet_relations to get all the relations that hold between its arguments word1 and word2, and then it uses the following heuristics to guess an answer:
To assess this function as well as the others defined below, I define an assessment function, which keeps track of the overall coverage and prints out an effectiveness summary for the items that the function does make predictions about:
The assessment is done by effectiveness(), which does standard precision, recall, and accuracy calculations for each class:
The assessment:
Where WordNet makes a guess, it is highly accurate, missing just two items. This is encouraging. However, the overall coverage is very slight, so we will need to recruit other information.
Next we recruit the IMDB review data. My expectation is that this will have better coverage but prove less accurate than WordNet.
If you followed along with the IMDB discussion through to the section on building scales, then you probably created a file called imdb-words-assess.csv. If not, you can get my versio here:
The function review_functions.get_all_imdb_scores, reads in this file and turns it into a Python dictionary mapping word-tag pairs to dictionaries of values {'Word':word, 'Tag':tag, 'ER':float, 'Coef':float: 'P':float}:
The following function uses p-values to restrict attention to just the linear coefficient values that we are willing to call reliable. If the p-value threshold isn't met, it returns None.
The prediction function compares coeffecient values. The first comparison checks to see whether they have the same sign. Differing signs are assumed to correspond to NO; these are pairs like good and bad. Once that comparison is made, we move to absolute values, using their size as a proxy for strength. This is simply an effecient way of making it so that, for example, bad has a "smaller" (less negative) coefficent than terrible.
And finally an assessment of the IMDB data on their own:
Still restricting attention to the one-worders, we carefully put the resources together into a single prediction function. In doing this, we favor WordNet, appealing to the reviews only where WordNet provides no information.
In addition, the function includes one additional inference: where neither of our resources makes a prediction, we venture a NO, on the grounds that unrelated predicates deliver this implicature via a Relevance-based calculation.
The whole is indeed better than its parts, in the sense that we are now cover the entire data set (though with a small drop in overall performance):
We can put it off no longer: abut 40% of the development set examples are not one-worders, so we need to generalize our approach to the complexities of multi-word expressions.
Both Wordnet and the reviews are comprised of data on single words, so our multi-word strategy needs to make use of those basic resources somehow. Some heuristics:
The following code implements this set of heuristics, drawing heavily on code we developed for the one-worders:
A new assessment method (one that doesn't restrict to one-worders):
Here is the output of assessment:
exercise ERROR, exercise FEATURES, exercise BIGRAMS
The performance of the determinisic model is pretty good, on the whole. We are well above chance on accuracy, and the precision and recall numbers show that we are making solid, educated guesses.
One unsatisfying thing about the model is that it is so hand-crafted. We decide ahead of time how to prioritize the information, and then we reduce it all to a single judgment. In doing this, we are likely hiding, ignoring, or obscuring many important factors.
The next model we develop addresses all these concerns. In my view, it allows us to be guided by specific scentific insights, but it also learns from the data we provide it. In general, its chief advantage is that it synthetizes a wide variety of information into a single predictive function, and it is also attentive to the data, in the sense that it is trained on, and therefore learns from, its details.
Maximum Entropy (MaxEnt) classification is a version of multinominal logistic regression. Since we'll deal with just two classes ('yes' and 'no') for our experiments, the model is effectively the same as a basic logistic regression model of the sort that we built with the review data.
One of the great strengths of MaxEnt models is that they are able to deal with lots of different kinds of features, and they deal reasonably well with correlations between predictors that can lead other models astray. What this means for us as linguists is that we are relatively free to define a lot of features that make sense to us scientifically, relying on the model to sort them out.
To get a feel for how the model works, it's useful to consider a simple model in which there is just one predictor. For this, let's use the difference in the cumulative coefficient scores between the question and the answer. The function for calcuating the cumulative score for each example is review_score_feature below. We'll take the diffence of the two values to be the sole predictor.
What we do at this point is reduce each item in the data to its feature vector. Here, our feature vectors have just one element in them — the float-valued difference between the scores. (For the models we develop below, we will map each item to a long and diverse feature vector.)
The model is then trained on some percentage of the data. For standard classification, this means is that we feed it pairs consisting of the correct label for the example and the associated feature vector.
However, there is one twist: each of our examples has, not one label, but rather 30 of them. We could take the majority label, but this would obscure the truly mixed message sent by some of our annotations. Thus, when training our model, we include each item 30 times, once for each label it has:
| item | annotation | review_score_diff | |
|---|---|---|---|
| 1 | 4015 | yes | -0.07 |
| 2 | 4015 | yes | -0.07 |
| ... | ... | ... | |
| 13 | 4015 | yes | -0.07 |
| 14 | 4015 | no | -0.07 |
| 15 | 4015 | no | -0.07 |
| ... | ... | ... | |
| 30 | 4015 | no | -0.07 |
| 31 | 4016 | yes | 0.00 |
The model then learns a weight associated with each of the predictors, based on the associations in the training data. For the actual example here, the weight it learns for the feature review_score_diff is 2.923 for the correct class being 'no'. (This weight will vary somewhat depending on the composition of the train/test split used.)
The prediction step then involves taking each feature vector and plugging it into the model equation. For example, if the feature vector is -0.07, as for Item 4015 above, then we calculate invlogit(3.331 * -0.07) = 0.56. That is, the model says that there is a 56% chance that this example is labeled 'no'. In turn, there is a 1.0-0.56 = 0.44 chance that the correct label is 'yes'.
In a regular classifications setting, we can simply take the larger of the two probabilities to be the predicted class. Since each of our examples has 30 labels, our method is slightly different. We take two basic approaches:
Each of these methods has advantages and disadvantages. Max-label is very easy to interpret, but it ignores a lot of the structure in our annotations. KL divergence embraces the uncertainty inherent in our annotations and predicted by our model, but it is hard to interpret in isolation, since the KL values don't mean much. In what follows, I use both methods together, comparing to baseline models to firm up our intuitions about what the numbers mean.
I now define a bunch of feature functions that we will use to reduce our items to feature vectors.
The deterministic model returns a definitive answer based on these simple relationships between the question and the answer. This often works well (Good? / Very good!), but it can also fail (Good? / Somewhat good.). With a MaxEnt model, we can include these features, expecting them to be balanced against other considerations.
We'll use negation in a variety of ways. This is the basis for those uses, and we'll also include it as a feature:
Figure NEGIMPACT helps to convey why the negation feature is important: encouraged is weaker than optimistic, suggesting a 'yes' reply, but the negation in the answer reverses this.
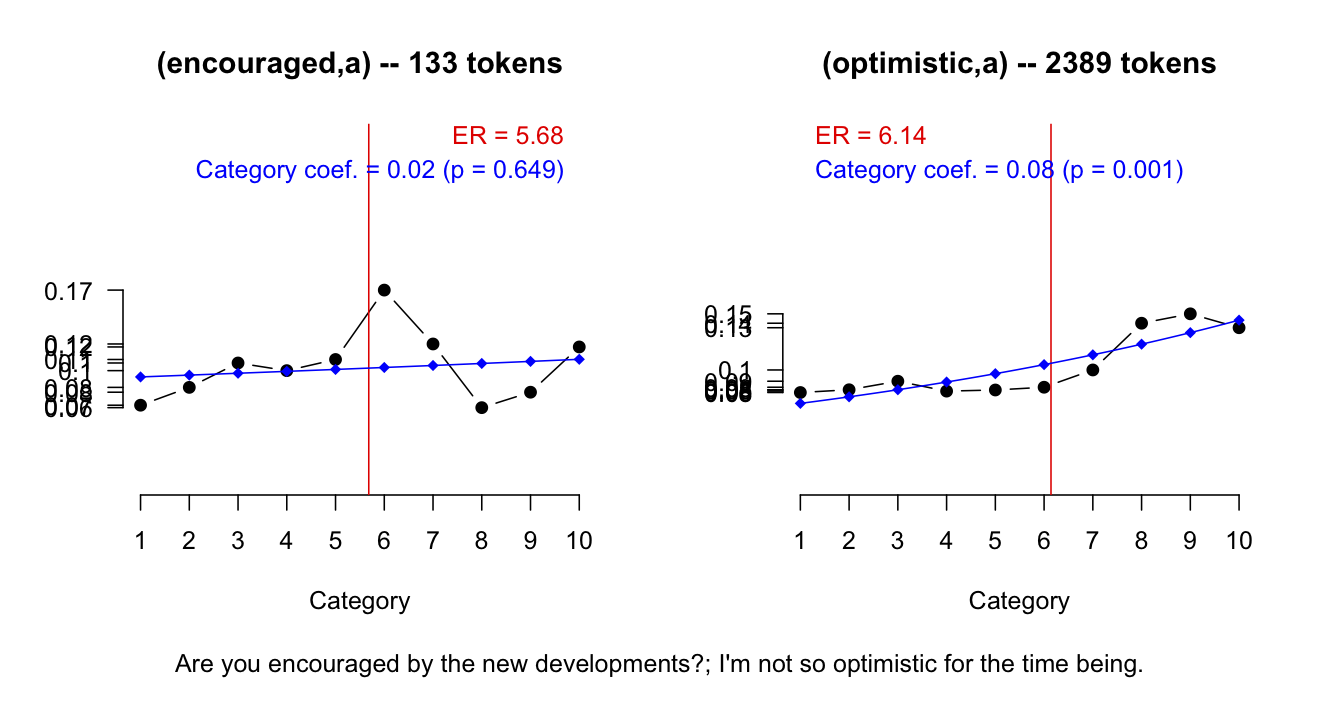
Figure NEGIMPACT was generated by the following code:
This function builds a total score for the words provided, based on the review data. It reverse the sign of the final score if negation_feature == True. The intended use of this argument is that we get the result of negation_feature(words) and use it here.
The reversal triggered where negation_feature == True is motivated by interactions like that of figure NEGIMPACT.
In addition to using the raw review scores, we also use this careful, pragmatically-informed comparison of them:
This function essentially acts as though each (question_word, answer_word) pair were the sole basis for prediction, using wordnet_word_predict from the deterministic experiment to make a YES/NO inference about each pairing:
The feature function puts all of the above pieces together:
Table RESULTS gives a set of results for the model:
Run Log-lik. Max-label acc. Mean KL div. Micro-avg prec. Micro-avg recall Train acc.
1 -0.48 0.8 0.54 0.88 0.73 0.81
2 -0.48 0.77 0.59 0.77 0.76 0.78
3 -0.4 0.83 0.43 0.85 0.83 0.78
4 -0.57 0.67 0.83 0.68 0.66 0.82
5 -0.49 0.7 0.65 0.71 0.69 0.81
6 -0.52 0.83 0.66 0.85 0.79 0.8
7 -0.39 0.8 0.49 0.83 0.79 0.79
8 -0.44 0.77 0.59 0.82 0.81 0.81
9 -0.51 0.73 0.55 0.78 0.7 0.82
10 -0.5 0.83 0.5 0.85 0.79 0.8
Means -0.48 0.77 0.58 0.8 0.76 0.8
An examination of the model's feature weights suggests that it is behaving sensibly. Table POS and table NEG provide information about the top indicators of 'yes' and 'no', respectively.
| Feature | Weight | Notes |
|---|---|---|
| a_score | 4.669 | High answer scores increase the probability of yes |
| similar_tos==True | 1.829 | similar_to is a kind of synonym relation |
| wn_yes==True | 1.688 | WordNet makes good predictions |
| q_score | 1.646 | High question scores increase the probability of yes |
| also_sees==True | 1.549 | also_see is a kind of synonym relation |
| subset==True | 1.500 | Restrictive modification does deliver 'yes', mostly |
| review_score_cmp==True | 0.339 | The reviews make good preditions (True is like 'yes'; see review_score_inference |
| derivationally_related_forms==True | 0.210 | derivational-relations preserve meaning |
| Feature | Weight | Notes |
|---|---|---|
| hyponyms==True | 1.856 | High answer scores increase the probability of yes |
| wn_no==True | 0.951 | similar_to is a kind of synonym relation |
| antonyms==True | 0.805 | WordNet makes good predictions |
| superset==True | 0.203 | High question scores increase the probability of yes |
| hypernyms==True | 0.146 | also_see is a kind of synonym relation |
| review_score_cmp==False | 0.094 | The reviews make good preditions (False is like 'no'; see review_score_inference |
| wn_None==True | 0.043 | Independence in WordNet creates Relevance implicatures. |
It is somewhat hard to think about the performance numbers in isolation. Some considerations:
To gain another baseline, I fit a model that simply uses word-counts inside the -CONTRAST predicates as features. (This experiment is run if iqap_classifier.py is run from the command-line.) This is a standard sort of baseline in natural language processing. The results are given in table UNIGRAMS:
Run Log-lik. Max-label acc. Mean KL div. Micro-avg prec. Micro-avg recall Train acc.
1 -0.3 0.83 0.57 0.83 0.83 1.0
2 -0.5 0.7 0.52 0.66 0.63 1.0
3 -0.39 0.77 0.57 0.77 0.76 1.0
4 -0.52 0.7 0.64 0.66 0.6 1.0
5 -0.51 0.63 0.78 0.58 0.57 1.0
6 -0.53 0.63 0.75 0.61 0.58 1.0
7 -0.47 0.7 0.64 0.7 0.65 1.0
8 -0.55 0.6 0.76 0.61 0.58 1.0
9 -0.43 0.73 0.59 0.75 0.71 1.0
10 -0.43 0.67 0.68 0.73 0.68 1.0
Means -0.46 0.7 0.65 0.69 0.66 1.0
I conclude that we have identified a number of important predictors, and they are working well together. Of course, there are lots of other possibilities to try. That's what most of the exercises are about, and this area is also ripe for projects.
exercise SENTI, exercise PROPAGATE, exercise CLASS, exercise PER
ERROR The assessment functions assess_one_worder_performance() and assess_performance() both have a second optional argument print_errors. If print_errors=True, then the function prints out the error examples. Using these functions, study the errors from one of these functions (with your choice of predictor function as the first argument), and draw some general lessons about the nature of the errors, with an eye towards making improvements.
FEATURES For the deterministic system, propose three modifications to features we used or three new features (or a mix of these options). Motivate each one, either by studying the data or (for bonus points) by implementing and assessing them on your own.
BIGRAMS The CSV file imdb-bigrams.csv.zip contains data on a large number of bigrams from the IMDB, in the following format:
Incorporate this information into the non-deterministic model. This is decidedly non-compositional, but it might help — there are some striking patterns in the bigram distributions, as seen in figure ADVADJ.
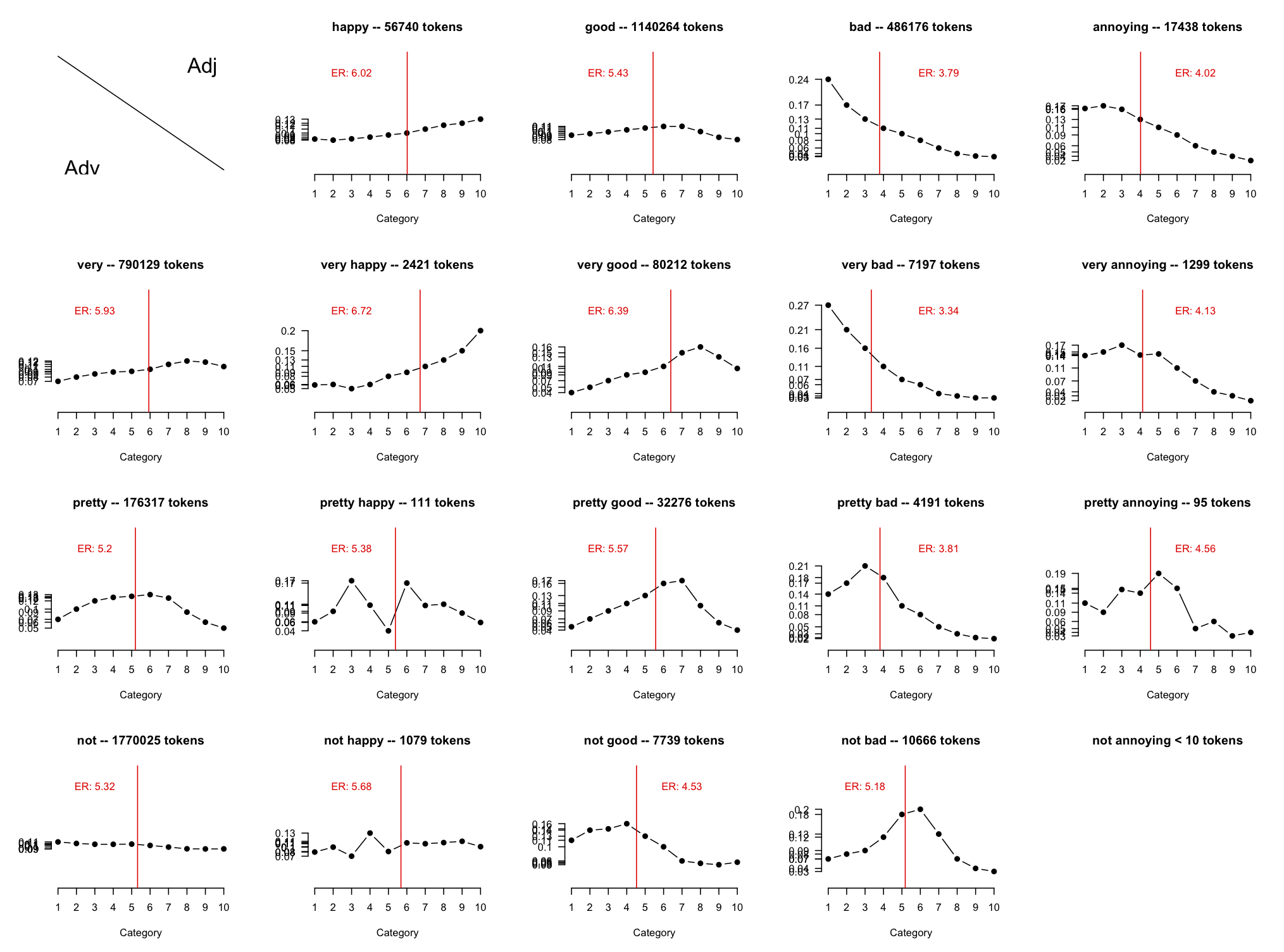
ERRORCMP If you run assess_performance(print_errors=True), you get a performance assessment for our deterministic model with the errors printed out. The following code does the same for a MaxEnt classifier model built from a random train/test split, using our central feature function:
Compare the errors from the deterministic and maxent models. How are they alike and how do they differ? What, if anything, do these findings tell us about which model to favor?
SENTI SentiWordNet provides another set of values, akin to the IMDB scores. Should we add these features to either one of the models? If so, how? If not, why not? For this, it might be useful to do this exercise comparing the SentiWordNet and IMDB values, to see what kind of new information the SentiWordNet scores would add.
PROPAGATE Blair Godensohn et al. 2008 propose an innovative method for learning sentiment information from WordNet using seed-sets of known sentiment words and a propagation algorithm. A Python/NLTK implementation of their algorithm is here, and the output of that algorithm run with the Harvard Inquirer as the seeds sets is wnscores_inquirer.csv.zip. (For more on the file's generation, see the readme file. For an overview of the algorithm, see page 12 of this handout.) Are these scores better or worse than the IMDB scores when it comes to making predictions about our dataset? You can answer this with whatever evidence you like: a direct comparison of the two lexicons, or a deterministic or maxent assessment.
CLASS NLTK includes a number of other classifier models. Perhaps modify/extend iqap_classifier.py so that the user can take advantage of one or more of these other models. (See also this project problem for an experimental/empirical angle on this coding project.)
PER For both the core MaxEnt experiment and the unigrams comparison (table UNIGRAMS), I used 80% of the development-set data for training. How do the models compare if we use less (perhaps much less) of the data for training? Do such experiments further support one model over the other?
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.