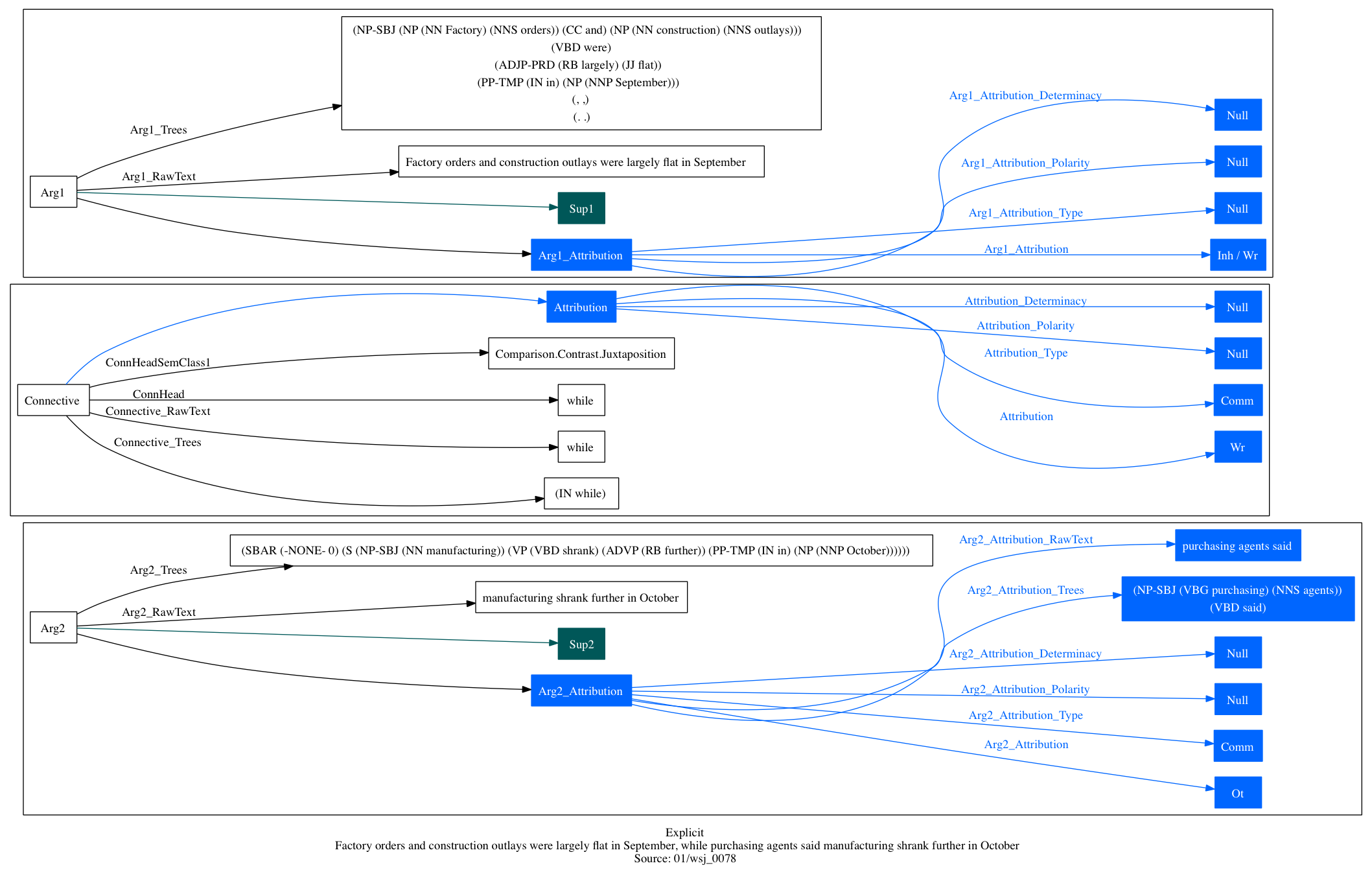
Figure WHILE
The structure of example (16) from Prasad et al. 2008
The Penn Discourse Treebank 2.0 (PDTB) is an incredibly rich resource for studying not only the way discourse coherence is expressed but also how information about discourse commitments (content attribution) is conveyed linguistically. The goal of this section is to provide an overview of the basic structure of the corpus and introduce you to some tools for working with it.
Associated reading:
Code and data:
With great power and richness comes great complexity, so bear with me... Let's start with an intuitive example from Prasad et al. 2008 to get a feel for what the corpus is like:
And the example in all its glory (here and throughout, click to enlarge):
This figure breaks down into three parts: Arg1, the connective, and Arg2. Within each, there is basic semantic and pragmatic information (black) as well as attribution information (blue). The Args can also have supplementary text (green), though this one doesn't have any.
The nodes containing heavily bracketed strings are the associated Penn Treebank 2.0 parsetrees. Each span of text (the _RawText nodes) has an associated set of such parsetrees.
The Institute has obtained a license for all of us to access the corpus for the purposes of this course, so I suggest that you download it in its usual distribution form:
The PDTB is a complex resource because it pools information from the Penn Treebank 2.0, both its merged parsetrees and its raw text. To make it easier for us to work with the corpus, I've created a single CSV file that pools (most of) the requisite information. I strongly suggest that you work with this version during the course:
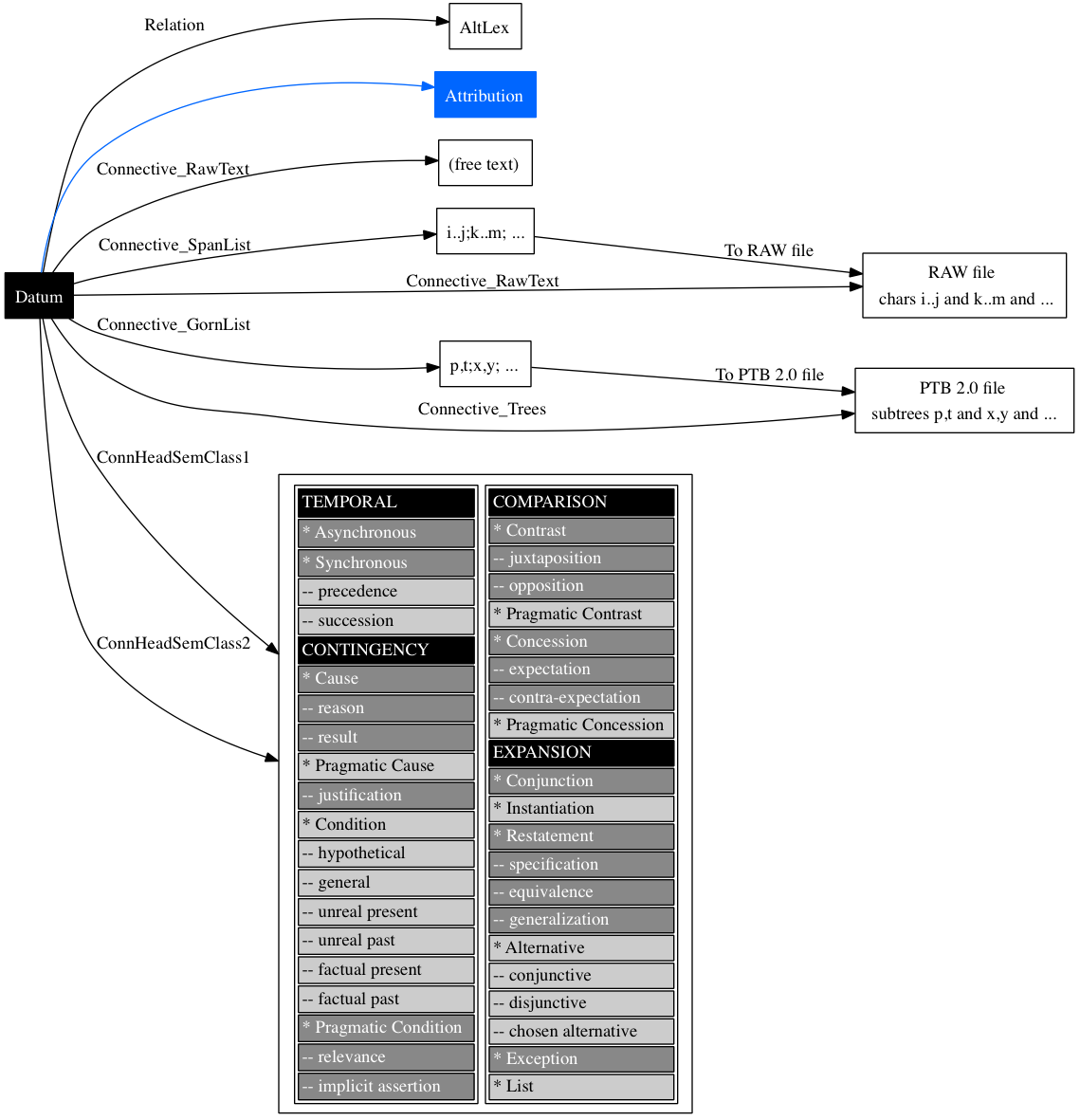
This is a large file with a lot of information in it. The basic structure is as follows: each row represents a single item (henceforth datum). There are 54 columns for each datum (though most of them are empty for a given example). These columns determine information like that depicted in figure WHILE.
The PDTB team has released a Java tool for searching and browsing. I myself won't be working with it, but it is flexible and powerful, so you might check it out if you dislike using Python or R.
The classes:
The main interface provided by pdtb.py is the CorpusReader:
The central method for CorpusReader objects is iter_data(), which allows you to iterate through the data in the corpus. Intuitively, iter_data() reads each row of the source csv file pdtb2.csv and turns it into a Datum object, which has lots of methods and attributes for doing cool things.
To test your set-up, paste the following code into a file, change the path to pdtb.py as needed (if it is in the same directory as pdtb.py, then you needn't do anything), and then run python on it.
If all goes well, your output will be the following table of relation-type counts, which is the same as Prasad et al. 2008, table 2 (though see their footnote for why the count for Implicit is slightly different).
In addition, pdtb.py allows you to create Datum objects directly from a string. For details on this, see Appendix A below.
It is possible to work with the PDTB in a limited way using just pdtb2.csv. Since it is a CSV file, it can be read into a program like Excel or R. For example, the following R code does exactly what the Python function relation_count() does:
As with the Switchboard Dialog Act Corpus, this has the potential to be a useful way of working with the corpus, but it will require you to write a lot of auxiliary functions to deal with the non-string and non-numeric values (trees, Gorn addresses, etc.), whereas pdtb.py does all of this for you.
Let's begin to unpack the PDTB. There is a lot of information to assimilate. The strategy I have taken is to give a high-level overview and some reference diagrams, and then hope that we can come to appreciate the details through some specific case studies.
Each datum in the PDTB has three basic parts: Arg1, the connective, and Arg2. Arg1 and Arg2 are always (heavily annotated) spans of text. The structure of the connective depends on the nature of the relation.
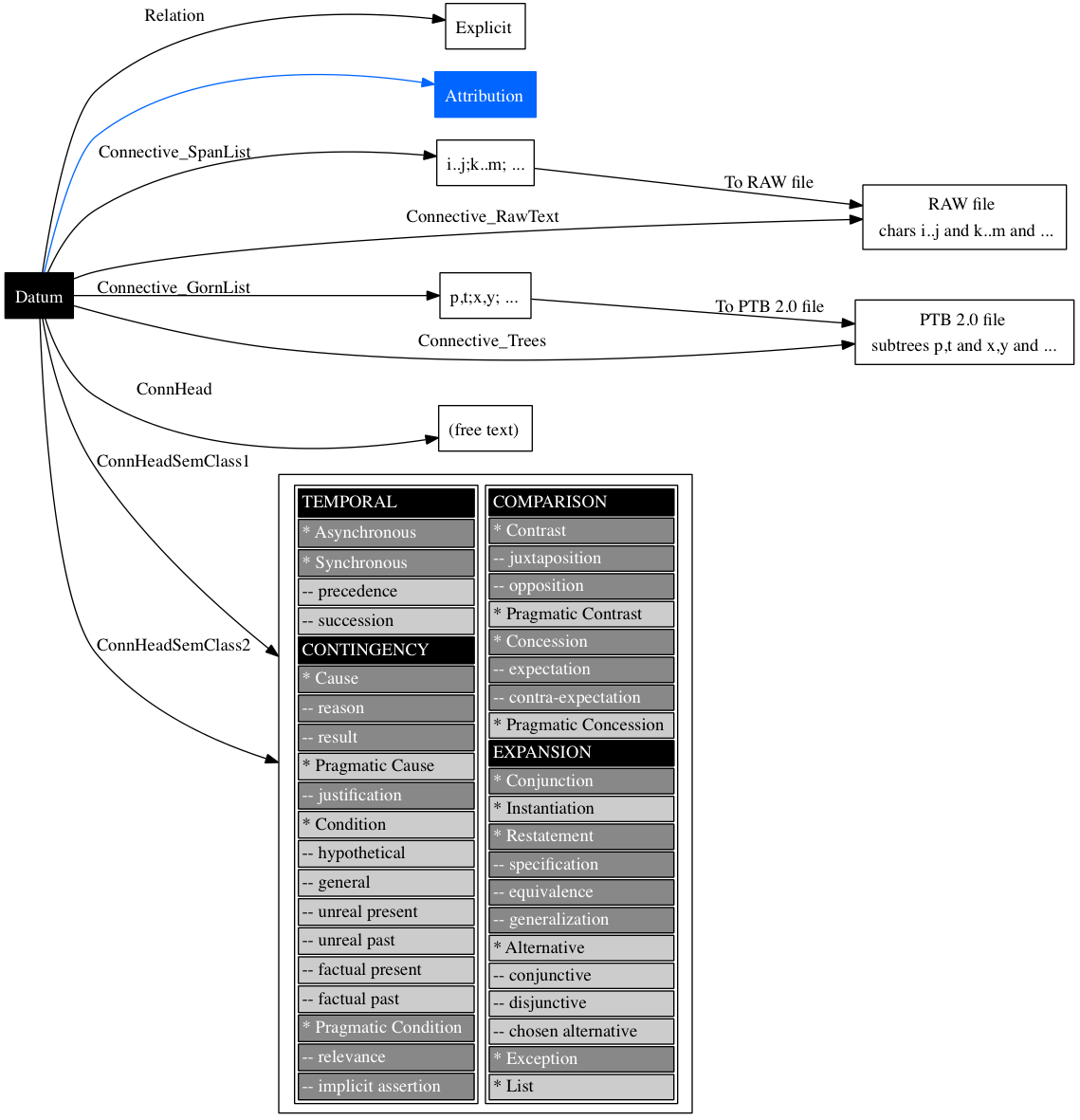
Table ATTRIBUTES provides a full listing of all the attributes of Datum instances. Thus, if dat is a Datum and att is an attribute, then dat.att wil return the corresponding value for that attribute.
| Attribute name | Object type | Applicable relations (None for others) | Description |
|---|---|---|---|
| Relation | str | Explicit|Implicit|AltLex|EntRel|NoRel | Explicit|Implicit|AltLex|EntRel|NoRel |
| Section | str | Explicit|Implicit|AltLex|EntRel|NoRel | 00 .. 24 |
| FileNumber | str | Explicit|Implicit|AltLex|EntRel|NoRel | 4-digit number where digits 1-2 == Section |
| Connective_SpanList | list | Explicit|AltLex | a list of lists where each member is a pair of integers |
| Connective_GornList | list | Explicit|AltLex | a list of lists where each member is a sequence of integers |
| Connective_RawText | str | Explicit|AltLex | raw text (same as obtainable with Connective_SpanList) |
| Connective_Trees | list | Explicit|AltLex | a list of nltk.tree.Tree objectives (same as obtainable with Connective_GornList) |
| Connective_StringPosition | int | Implicit|EntRel|NoRel | the position of the inferred relation for Implicit |
| SentenceNumber | int | Implicit|EntRel|NoRel | number of the source sentence in the raw and parsed files |
| ConnHead | str | Explicit | the head of the connective string (which could be phrasal) |
| Conn1 | str | Implicit | the obligatory inferred connective |
| Conn2 | str | Implicit | an optional second connective |
| ConnHeadSemClass1 | str | Explicit|Implicit|AltLex | the semantic class of Conn1; see the gray table in EXPLICIT |
| ConnHeadSemClass2 | str | Explicit|Implicit|AltLex | optional second semantic class for Conn1, drawn from the same values as ConnHeadSemClass1 |
| Conn2SemClass1 | str | Implicit | the semantic class of Conn2 if present; see the gray table in EXPLICIT |
| Conn2SemClass2 | str | Implicit | optional second semantic class for Conn2 if present, drawn from the same values as ConnHeadSemClass1 |
| Attribution_Source | str | Explicit|Implicit|AltLex | Wr|Ot|Arb |
| Attribution_Type | str | Explicit|Implicit|AltLex | Comm|PAtt|Ftv|Ctrl |
| Attribution_Polarity | str | Explicit|Implicit|AltLex | Neg|Null |
| Attribution_Determinacy | str | Explicit|Implicit|AltLex | Indet|Null |
| Attribution_SpanList | list | Explicit|Implicit|AltLex | a list of lists where each member is a pair of integers |
| Attribution_GornList | list | Explicit|Implicit|AltLex | a list of lists where each member is a sequence of integers |
| Attribution_RawText | str | Explicit|Implicit|AltLex | raw text (same as obtainable with Attribution_SpanList) |
| Arg1_SpanList | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of lists where each member is a pair of integers |
| Arg1_GornList | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of lists where each member is a sequence of integers |
| Arg1_RawText | str | Explicit|Implicit|AltLex|EntRel|NoRel | raw text (same as obtainable with Arg1_SpanList) |
| Arg1_Trees | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of nltk.tree.Tree objectives (same as obtainable with Arg1_GornList) |
| Arg1_Attribution_Source | str | Explicit|Implicit|AltLex | Wr|Ot|Arb|Inh |
| Arg1_Attribution_Type | str | Explicit|Implicit|AltLex | Comm|PAtt|Ftv|Ctrl |
| Arg1_Attribution_Polarity | str | Explicit|Implicit|AltLex | Neg|Null |
| Arg1_Attribution_Determinacy | str | Explicit|Implicit|AltLex | Indet|Null |
| Arg1_Attribution_SpanList | list | Explicit|Implicit|AltLex | a list of lists where each member is a pair of integers |
| Arg1_Attribution_GornList | list | Explicit|Implicit|AltLex | a list of lists where each member is a sequence of integers |
| Arg1_Attribution_RawText | str | Explicit|Implicit|AltLex | raw text (same as obtainable with Arg1_Attribution_SpanList) |
| Arg1_Attribution_Trees | lost | Explicit|Implicit|AltLex | list of nltk.tree.Tree objectives (same as obtainable with Arg1_Attribution_GornList) |
| Arg2_SpanList | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of lists where each member is a pair of integers |
| Arg2_GornList | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of lists where each member is a sequence of integers |
| Arg2_RawText | str | Explicit|Implicit|AltLex|EntRel|NoRel | raw text (same as obtainable with Arg2_SpanList) |
| Arg2_Trees | list | Explicit|Implicit|AltLex|EntRel|NoRel | a list of nltk.tree.Tree objectives (same as obtainable with Arg2_GornList) |
| Arg2_Attribution_Source | str | Explicit|Implicit|AltLex | Wr|Ot|Arb|Inh |
| Arg2_Attribution_Type | str | Explicit|Implicit|AltLex | Comm|PAtt|Ftv|Ctrl |
| Arg2_Attribution_Polarity | str | Explicit|Implicit|AltLex | Neg|Null |
| Arg2_Attribution_Determinacy | str | Explicit|Implicit|AltLex | Indet|Null |
| Arg2_Attribution_SpanList | list | Explicit|Implicit|AltLex | a list of lists where each member is a pair of integers |
| Arg2_Attribution_GornList | list | Explicit|Implicit|AltLex | a list of lists where each member is a sequence of integers |
| Arg2_Attribution_RawText | str | Explicit|Implicit|AltLex | raw text (same as obtainable with Arg2_Attribution_SpanList) |
| Sup1_SpanList | list | Explicit|Implicit|AltLex | a list of lists where each member is a pair of integers |
| Sup1_GornList | list | Explicit|Implicit|AltLex | a list of lists where each member is a sequence of integers |
| Sup1_RawText | str | Explicit|Implicit|AltLex | optional supporting text for Arg1 (same as obtainable with Sup1_SpanList) |
| Sup1_Trees | list | Explicit|Implicit|AltLex | list of nltk.tree.Tree objectives (same as obtainable with Sup1_GornList) |
| Sup2_SpanList | list | Explicit|Implicit|AltLex | a list of lists where each member is a pair of integers |
| Sup2_GornList | list | Explicit|Implicit|AltLex | a list of lists where each member is a sequence of integers |
| Sup2_RawText | str | Explicit|Implicit|AltLex | optional supporting text for Arg1 (same as obtainable with Sup2_SpanList) |
| Sup2_Trees | list | Explicit|Implicit|AltLex | list of nltk.tree.Tree objectives (same as obtainable with Sup2_GornList) |
The next few subsections work to make this clearer with diagrams.
There are five types of connective: Explicit, Implicit, AltLex, EntRel, and NoRel. The following characterizations and examples are from Prasad et al. 2008.
Prasad et al. 2008: "Explicit connectives are drawn from three grammatical classes: subordinating conjunctions (e.g., because, when, etc.), coordinating conjunctions (e.g., and, or, etc.), and discourse adverbials (e.g., for example, instead, etc.)."
Here is example from above repeated without its trees and Args.
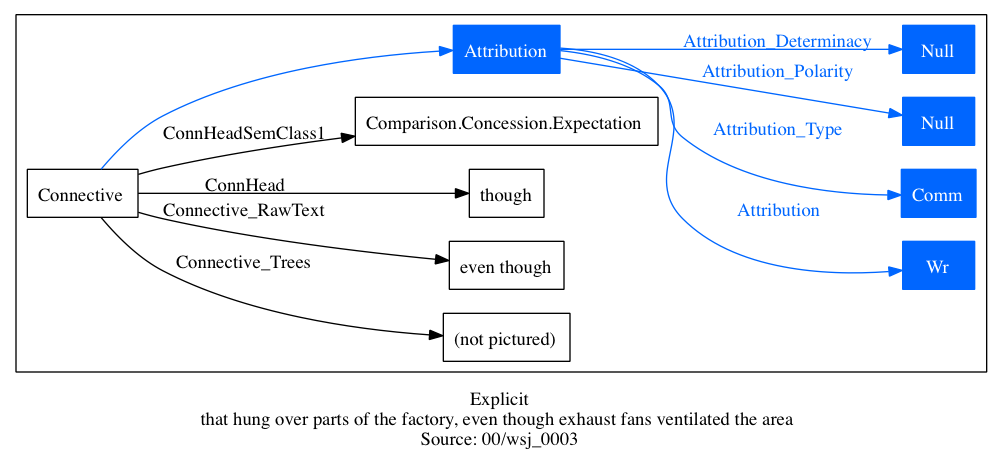
Here is the abstract structure of such connectives:
Prasad et al. 2008: "[S]uch inferred relations are annotated by inserting a connective expression — called an 'Implicit' connective — that best expresses the inferred relation"
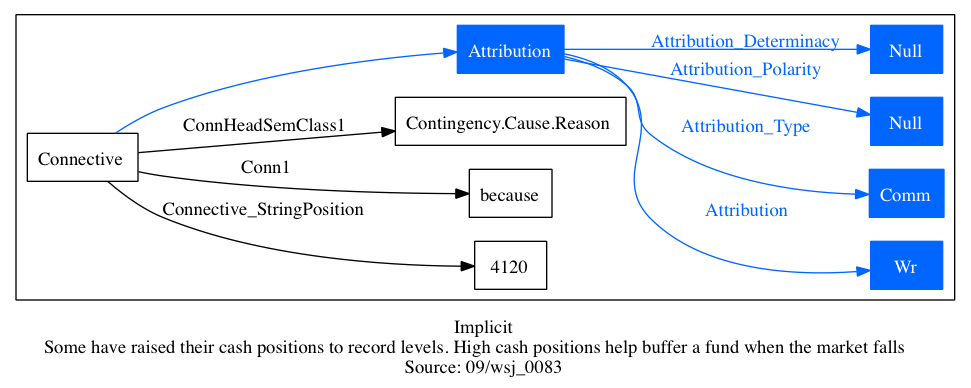
Figure IMPLICIT gives the abstract structure of such connectives:

Prasad et al. 2008: "the insertion of an Implicit connective to express an inferred relation led to a redundancy due to the relation being alternatively lexicalized by some non-connective expression"
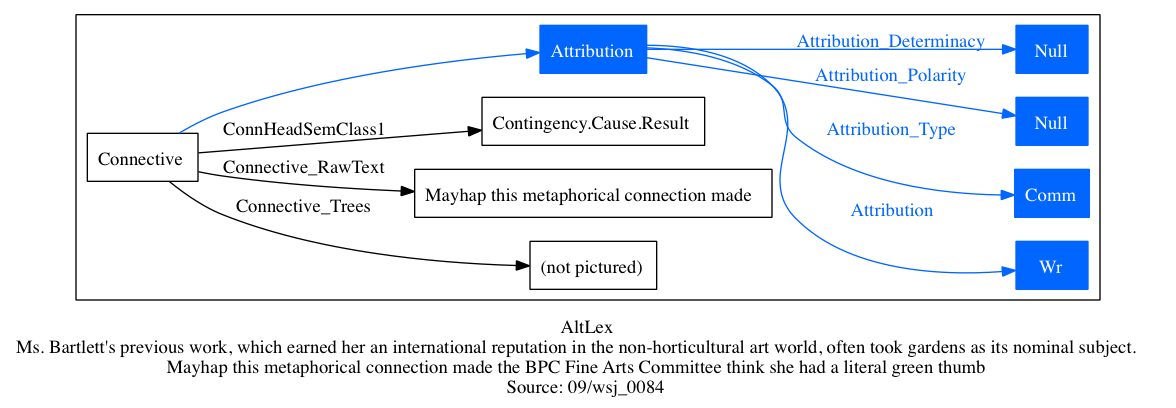
Figure ALTLEX depicts the general structure:
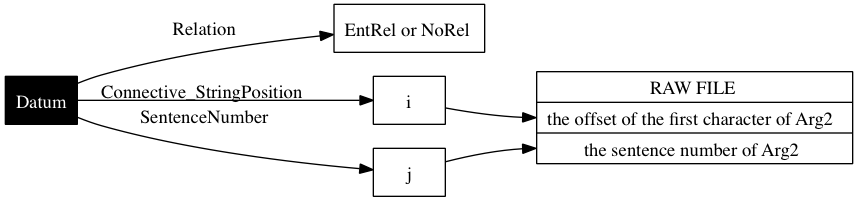
Prasad et al. 2008 on EntRel: "only an entity-based coherence relation could be perceived between the sentences"
Prasad et al. 2008 on NoRel: "no discourse relation or entity-based relation could be perceived between the sentences"
Very few things are defined for these, as the abstract structure, figure ENTNO, shows.
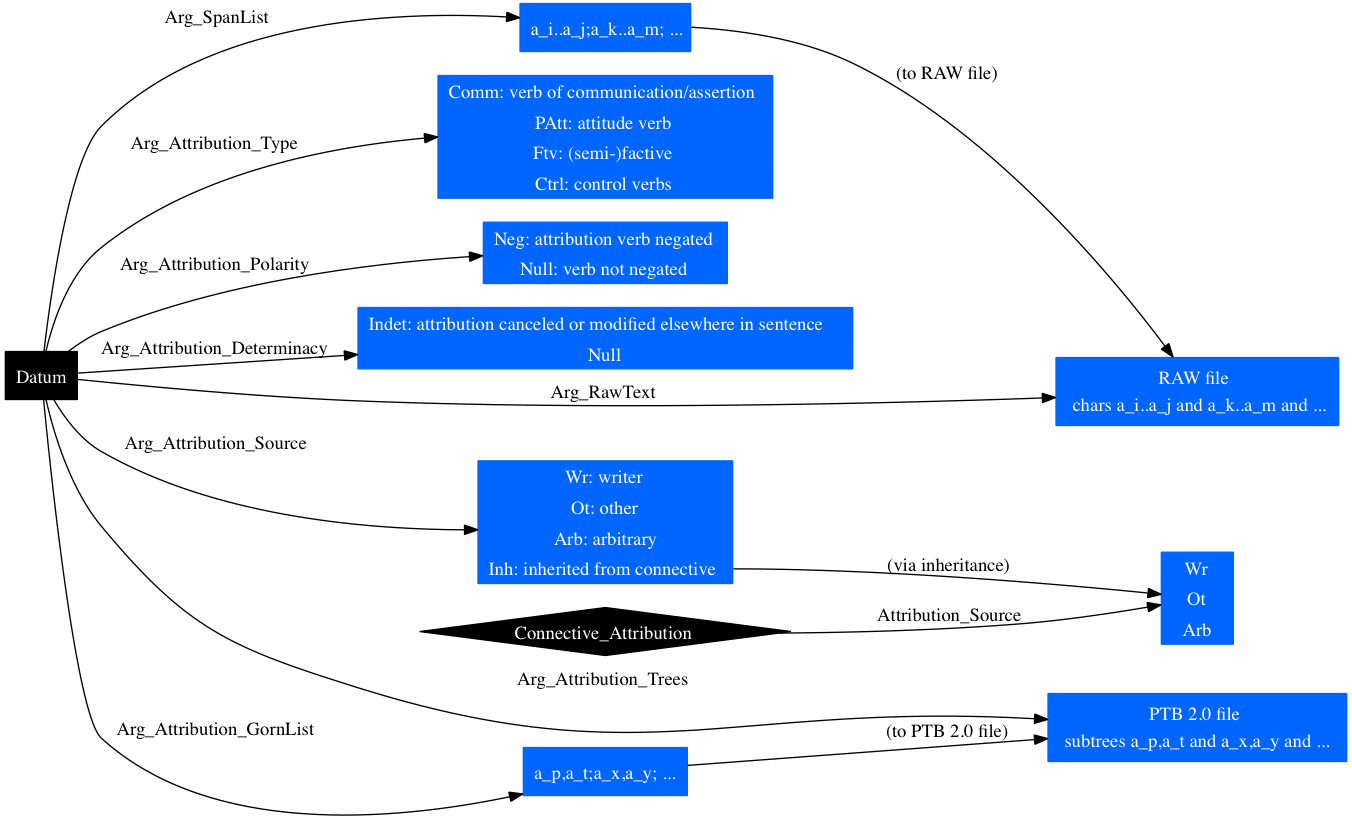
The arguments each have (i) basic attributes for their content (the raw text and the trees) as well as (ii) attribution informtion and (iii) supplementary text helping to contextualize the content.
The arguments always have basic information. Supplementary text is somewhat rarer. Attribution text is always present for Implicit, Explicit, and AltLex, and it is alway absent for EntRel and NoRel.
Figure ARG shows the full structure, though without the Attribution information. Each edge label corresponds to an an attribute of Datum objects as long as you insert 1 or 2 after Arg for each one.

Figure ATTRIBUTION breaks down the structure of attributions, showing the relevant attributes as edge labels (insert 1 or 2 after Arg) and the range of values on the nodes, with description.
The Arg_Attribution_Source value Inh means that the attribution is inherited from the connective. The Datum methods final_arg1_attribution_source() and final_arg2_attribution_source() handle this for you, providing the final attribution value in every case.
There are lots of different kinds of text to work with:
For each of these, there are associated methods for getting at their structure. For example:
There are similarly named methods for Sups, connectives, and attributions.
The SpanList and GornList attributes are for connecting with the Penn Treebank files. The relevant material is already inserted into the CSV file and accessible via the _RawText and _Trees attributes, so you probably won't need it, but it is there just in case you need to connect with the external files.
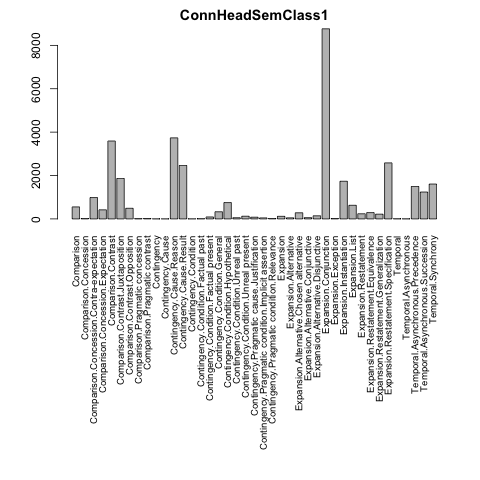
The function count_semantic_classes() looks at the values for ConnHeadSemClass1, which gives the primary sense for the connective for Implicit, Explicit, and AltLex data.
The following uses count_semantic_classes to sort the output from most to least frequent and put it into a CSV file.
The output has 41 lines, one for each relation seen in the gray and black tables for Explicit, Implicit, and AltLex. The following R code turns this into a barplot with (I think) readable labels):
exercise SEMCLASSES, exercise CM, exercise MAINVERB, exercise WORDS
There is no single attribute of Datum objects that provides an accurate high-evel summary of its nature:
Therefore, Datum objects include the method conn_str for getting at the above strings directly. The code datum.conn_str() will return the above-listed values. The following code uses this method to gather counts of all of the different regularized heads:
The resulting dictionary is long:
To summarize this, a function for mapping this into a format that Wordle can understand:
Here is the result of pasting the sublists into the Wordle advanced function:



exercise WORDLEEX, exercise ROOTS
The basic distribution of attribution values.
And the output:
A simple look at the nature of the attributions:
The top of the output of print_attribution_texts() (the frequent repeats are due to the fact that individual spans of text are often involved in multiple relationships):
The Datum method relative_arg_order() determines the ordering of Arg1 and Arg2. Its values:
The function distribution_of_relative_arg_order() in pdtb_functions.py calculates the distribution of these orderings. Here is the output:
As expected, it is most common for Arg1 to precede Arg2. The two 'overlap' relations, arg2_precedes_and_overlaps_but_does_not_contain_arg1 and arg1_precedes_and_overlaps_but_does_not_contain_arg2, turn out to be non-attested.
The Datum methods arg1_precedes_arg2(), arg1_contains_arg2(), arg1_precedes_and_overlaps_but_does_not_contain_arg2(), arg2_precedes_arg1(), arg2_contains_arg1(), and arg2_precedes_and_overlaps_but_does_not_contain_arg1() allow for quick identification of these subsets. Each returns True or False.
The best way to get acquainted with a new large-scale corpus resource is to hypothesize that important relationships might exist between two of its properties and then test to see whether the hypothesis holds up.
The function contingencies() in pdtb_functions.py seeks to provide a general method for exploring such relationships at the level of properties of Datum objects.
This function takes as its arguments two functions on Datum instances and calculates the observed/expected (O/E) values for the two classes of results. The print-out includes the observed contingency table, the expected contingency table, and an ordered list of O/E values. Values of None are ignored and can thus be used as a filter.
The following code tests for associations between relation-type and the primary semantic classes:
The output:
Values above 1 indicate that the observed values are larger than we would expect given the null hypothesis that the two variables are independent of each other. Values below 1 indicate that the observed values are small than we would expect given this hypothesis.
The Count table can be the input to chisq.test and g.test in R. However, the counts involved in these tables are so large that the null hypothesis is almost certain to look false, so a more qualitative assessment might be called for, followed by more articulated regression modeling.
The output:
The following code tests for associations between relative argument ordering and the primary semantic class:
The output:
The following explores the relationship between argument ordering and the nature of connective's cannonical name:
Here's a sample of the ranked output (the contingency tables are too large to display usefully here):
Chris Brown suggested looking at patterns of negation across the two Args — both where the negations are imbalanced and where they are balanced. The following adapts his own code for exploring this issue:
The output ranking:
This looks like solid support for Chris's hypothesis that mismatches in negation would assoicate with Comparison relations.
You can create Datum objects directly from a string. The idea is that you might copy and paste a row out of pdtb.csv so that you can work with it directly. It's unwieldy, but it is useful for looking at specific examples:
The datum method to_graphiviz() will generate a Graphviz representation, as a plain-text file. If you then open that file with Graphviz, you should get a nice image that you can save.
The Graphviz language is easy to learn (I advise studying the gallery of examples), and it is a flexible, powerful way to visualize data.
SEMCLASSES Modify count_semantic_classes() so that it counts only via the highest level semantic classifications, by splitting ConnHeadSemClass1 values on the leftmost period and using only the first element. Provide your modified code and the output counts.
CM Construct a confusion matrix with the Relation types as rows, the ConnHeadSemClass1 as colums, and the cells representing the number of times that the correspondong row and columns values occur together. Are there patterns here that we might take advantage of in experiments predicting Relation-types or semantic coherence classes?
WORDS The Datum method calls arg1_pos(wn_format=True, lemmatize=True) and arg2_pos(wn_format=True, lemmatize=True) return the stemmed (word, pos) pairs for Arg1 and Arg2. Use these functions to try to find words that are predictive of ConnHeadSemClass1 values. I suggest constructing count dictionaries and looking at the relationships between counts, but feel free to try something more ambitious.
MAINVERB Explore the role that main predicates play in determining coherence relations. To do this, you'll need to:
I leave the exact formulation of this problem to you. You might want to restriction attention to one of the Args, or use both of them. You might want to look only at verbs (and perhaps stem them to address sparseness problems; see wn_string_lemmatizer in wordnet_functions.py). And so forth; just be sure to explain what you did and why; I myself am not sure how best to go about this.
WORDLEEX The Wordle digrams in figure WORDLE depict the nature of the connectives in Explicit, Implicit, and AltLex relations. The pictures are quite different. Pick a connective and offer an explanation for its distribution across these relation categories.
ROOTS Study the relationship between the root node labels for Arg1 and Arg2 and the value of conn_str(). In the spirit of the earlier clause-typing experiment, what do the associations say about clause-types and discourse coherence?
ATT Explore the output of print_attribution_texts(). What semantic relationships recur in the list? What might this tell us about the nature of speaker commitment?
Home
 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.